






Р’ СҖСғРұСҖРёРәСғ "РЎРёСҒСӮРөРјСӢ РәРҫРҪСӮСҖРҫР»СҸ Рё СғРҝСҖавлРөРҪРёСҸ РҙРҫСҒСӮСғРҝРҫРј (РЎРҡРЈР”)" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№

Р Р°СҒРҝРҫР·РҪаваРҪРёРө лиСҶ РҪахРҫРҙРёСӮСҒСҸ РІ СӮСҖРөРҪРҙРө РәР°Рә РҫРҙРҪР° РёР· РҪаиРұРҫР»РөРө РІРҫСҒСӮСҖРөРұРҫРІР°РҪРҪСӢС… СӮРөС…РҪРҫР»РҫРіРёР№ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРҫР№ РёРҙРөРҪСӮифиРәР°СҶРёРё. РҹСҖРҫРІРҫРҙРёСӮСҒСҸ РұРҫР»СҢСҲРө РәРҫлиСҮРөСҒСӮРІРҫ РІСҒРөРІРҫР·РјРҫР¶РҪСӢС… СӮРөСҒСӮРҫРІ Рё РәРҫРҪРәСғСҖСҒРҫРІ РҪР° РҝСҖРөРҙРјРөСӮ РІСӢСҸРІР»РөРҪРёСҸ Р»СғСҮСҲРөРіРҫ алгРҫСҖРёСӮРјР°, Рё РІ РіРҫР»Рҫвах СӮРөС…, РәСӮРҫ СҮРёСӮР°РөСӮ РёС… СҖРөР·СғР»СҢСӮР°СӮСӢ, СҒРәлаРҙСӢРІР°РөСӮСҒСҸ РҪРөРҫРҙРҪРҫР·РҪР°СҮРҪР°СҸ РәР°СҖСӮРёРҪР° - РҫРәазСӢРІР°РөСӮСҒСҸ, СҮСӮРҫ СҮРөРјРҝРёРҫРҪРҫРІ РјРёСҖР° РұРҫР»СҢСҲРҫРө РәРҫлиСҮРөСҒСӮРІРҫ. Рҳ РІРҫР·РҪРёРәР°РөСӮ РІРҫРҝСҖРҫСҒ: РәР°РәРҫР№ алгРҫСҖРёСӮРј РҪР° СҒамРҫРј РҙРөР»Рө Р»СғСҮСҲРёР№?
Р’ СҚСӮРҫР№ СҒСӮР°СӮСҢРө РјСӢ РҝРҫРіРҫРІРҫСҖРёРј Рҫ СӮРҫРј, РҝРҫ РәР°РәРёРј РҝР°СҖамРөСӮСҖам РҫСҶРөРҪРёРІР°СҺСӮСҒСҸ алгРҫСҖРёСӮРјСӢ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ лиСҶ, РәР°РәРёРө РІРҫРҝСҖРҫСҒСӢ Р·Р°РҙаваСӮСҢ СҖазСҖР°РұРҫСӮСҮРёРәам Рё РәР°Рә РҝСҖавилСҢРҪРҫ РҝСҖРҫРІРөСҒСӮРё СӮРөСҒСӮРёСҖРҫРІР°РҪРёРө СҒРёСҒСӮРөРјСӢ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ РҙР»СҸ РәРҫРҪРәСҖРөСӮРҪРҫРіРҫ РҝСҖРҫРөРәСӮР°.
РЎСҖРөРҙРё РјРҪРҫРіРҫСҮРёСҒР»РөРҪРҪСӢС… РәРҫРҪРәСғСҖСҒРҫРІ, СҒРІСҸР·Р°РҪРҪСӢС… СҒ СҖР°СҒРҝРҫР·РҪаваРҪРёРөРј лиСҶ, РҫСҒРҪРҫРІРҪСӢРјРё СҸРІР»СҸСҺСӮСҒСҸ СҒР»РөРҙСғСҺСүРёРө:
1. LFW (РЈРҪРёРІРөСҖСҒРёСӮРөСӮ РңР°СҒСҒР°СҮСғСҒРөСӮСҒР°). РқаиРұРҫР»РөРө СҒСӮР°СҖСӢР№ РәРҫРҪРәСғСҖСҒ, РҫРҪ РҝСҖРҫРІРҫРҙРёСӮСҒСҸ РҪР° РҝСҖРҫСӮСҸР¶РөРҪРёРё РұРҫР»РөРө РҝСҸСӮРё Р»РөСӮ, СҒРјРөРҪРёР»РҫСҒСҢ РҪРөСҒРәРҫР»СҢРәРҫ РҝРҫРәРҫР»РөРҪРёР№ РҝРҫРұРөРҙРёСӮРөР»РөР№. РқРҫ СҒ СӮРҫСҮРәРё Р·СҖРөРҪРёСҸ СғСҖРҫРІРҪСҸ СҒРҫРІСҖРөРјРөРҪРҪСӢС… СӮРөС…РҪРҫР»РҫРіРёР№ РҫРҪ СғР¶Рө лиСҲРёР»СҒСҸ СҒРјСӢСҒла. Р’ РҪРөРј РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ РҫСӮРҪРҫСҒРёСӮРөР»СҢРҪРҫ РҪРөРұРҫР»СҢСҲР°СҸ Рұаза, РҪР° РәРҫСӮРҫСҖРҫР№ Р·РҪР°СҮРёСӮРөР»СҢРҪР°СҸ СҮР°СҒСӮСҢ СҒРҫРІСҖРөРјРөРҪРҪСӢС… алгРҫСҖРёСӮРјРҫРІ РҝРҫРәазСӢРІР°РөСӮ РҙРҫСҒСӮРҫР№РҪСӢРө СҖРөР·СғР»СҢСӮР°СӮСӢ - Сғ 32 СғСҮР°СҒСӮРҪРёРәРҫРІ СғСҖРҫРІРөРҪСҢ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ РІСӢСҲРө 99%, Рё, РіР»СҸРҙСҸ РҪР° СӮР°РәСғСҺ РҝР»РҫСӮРҪРҫСҒСӮСҢ, РІСӢРұСҖР°СӮСҢ Р»СғСҮСҲРёС… РҝСҖР°РәСӮРёСҮРөСҒРәРё РҪРөРІРҫР·РјРҫР¶РҪРҫ.
2. MegaFace (РЈРҪРёРІРөСҖСҒРёСӮРөСӮ ДжРҫСҖРҙжа Р’Р°СҲРёРҪРіСӮРҫРҪР°). РҘРҫСҖРҫСҲ СӮРөРј, СҮСӮРҫ РёСҒРҝРҫР»СҢР·СғРөСӮ РұРҫР»СҢСҲСғСҺ РұазСғ РҙРөСҒСӮСҖСғРәСӮРҫСҖРҫРІ - РҝРҫСҖСҸРҙРәР° 1 РјР»РҪ лиСҶ. РӯСӮРҫ РҝРҫР·РІРҫР»СҸРөСӮ РёР·РјРөСҖРёСӮСҢ СҖР°РұРҫСӮСғ алгРҫСҖРёСӮРјРҫРІ РІ РҫСҮРөРҪСҢ СҲРёСҖРҫРәРҫРј РҙРёР°РҝазРҫРҪРө, РІ СӮРҫРј СҮРёСҒР»Рө РҝСҖРё малРөРҪСҢРәРёС… РҫСҲРёРұРәах Р»РҫР¶РҪРҫРіРҫ РҝСҖРёРҪСҸСӮРёСҸ (РҪР° СғСҖРҫРІРҪРө 10-7). БлагРҫРҙР°СҖСҸ СҚСӮРҫРјСғ СҖазРҪРёСҶР° РјРөР¶РҙСғ СҖазлиСҮРҪСӢРјРё алгРҫСҖРёСӮмами РІСӢРіР»СҸРҙРёСӮ Р·РҪР°СҮРёРјРҫ РҫСӮСҖСӢРІ 1 - РіРҫ РјРөСҒСӮР° РҫСӮ 2-РіРҫ РҙРҫ РҪРөРҙавРҪРөРіРҫ РІСҖРөРјРөРҪРё СҒРҫСҒСӮавлСҸР» 8%. РһРҙРҪР°РәРҫ, СҒРөР№СҮР°СҒ РҙиффРөСҖРөРҪСҶиалСҢРҪР°СҸ Р·РҪР°СҮРёРјРҫСҒСӮСҢ СҚСӮРҫРіРҫ СӮРөСҒСӮР° СӮР°РәР¶Рө СҒРҪижаРөСӮСҒСҸ.
3. FRVT (РҗРјРөСҖРёРәР°РҪСҒРәРёР№ РёРҪСҒСӮРёСӮСғСӮ СҒСӮР°РҪРҙР°СҖСӮРҫРІ NIST). РқаиРұРҫР»РөРө СҖРөРҝСҖРөР·РөРҪСӮР°СӮРёРІРҪСӢР№ СӮРөСҒСӮ РҪР° РҙР°РҪРҪСӢР№ РјРҫРјРөРҪСӮ. РӯСӮРҫ РҪР°СҒСӮРҫСҸСүРөРө Р°РәР°РҙРөРјРёСҮРөСҒРәРҫРө РҪР°СғСҮРҪРҫРө РёСҒСҒР»РөРҙРҫРІР°РҪРёРө, Р° РҪРө РәРҫРҪРәСғСҖСҒ, РіРҙРө СҖазРҙР°СҺСӮСҒСҸ РјРөСҒСӮР°. РһСӮСҮРөСӮ СҒРҫСҒСӮавлСҸРөСӮ РҫРәРҫР»Рҫ 80 СҒСӮСҖР°РҪРёСҶ, РҝСҖРҫРҙРҫлжаСҺСӮ РҝСғРұлиРәРҫРІР°СӮСҢСҒСҸ РҪРҫРІСӢРө СҖРөР·СғР»СҢСӮР°СӮСӢ, Рё РҫРҪ РҫСӮСҖажаРөСӮ Р°РәСӮСғалСҢРҪСӢР№ СҒСҖРөР· РёРҪРҙСғСҒСӮСҖРёРё СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ лиСҶ. Р—РҙРөСҒСҢ РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ СҖазлиСҮРҪСӢРө РұазСӢ, Рё РІ РёСӮРҫРіРө РҝРҫР»СғСҮР°РөСӮСҒСҸ РҫРұСҠРөРјРҪР°СҸ РәР°СҖСӮРёРҪР° СӮРҫРіРҫ, РәР°Рә алгРҫСҖРёСӮРјСӢ СҖР°РұРҫСӮР°СҺСӮ РІ СҖазРҪСӢС… СғСҒР»РҫРІРёСҸС….
РҡРҫРіРҙР° СҖРөСҮСҢ РёРҙРөСӮ РҫРұ алгРҫСҖРёСӮмах СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ, РІСҒРөРіРҙР° РҪСғР¶РҪРҫ РҫРұСҖР°СүР°СӮСҢ РІРҪРёРјР°РҪРёРө РҪР° РҙРІР° СӮРёРҝР° РҫСҲРёРұРҫРә, РәРҫСӮРҫСҖСӢРө СӮРөСҒРҪРҫ СҒРІСҸР·Р°РҪСӢ РјРөР¶РҙСғ СҒРҫРұРҫР№
Р’ СҖРөР·СғР»СҢСӮР°СӮРө СҒСҖавРҪРөРҪРёСҸ лиСҶР° СҮРөР»РҫРІРөРәР° СҒ СҚСӮалРҫРҪРҫРј РІСӢРҙР°РөСӮСҒСҸ РҝР°СҖамРөСӮСҖ, РәРҫСӮРҫСҖСӢР№ РҪазСӢРІР°РөСӮСҒСҸ "СҒСӮРөРҝРөРҪСҢ РҝРҫС…РҫР¶РөСҒСӮРё". РһСҮРөРҪСҢ СҮР°СҒСӮРҫ РөРө РҝСғСӮР°СҺСӮ СҒ РІРөСҖРҫСҸСӮРҪРҫСҒСӮСҢСҺ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ. РһРұСӢСҮРҪРҫ СҒСӮРөРҝРөРҪСҢ РҝРҫС…РҫР¶РөСҒСӮРё РҪРҫСҖРјРёСҖРҫРІР°РҪР° РҫСӮ 0 РҙРҫ 100, СҮСӮРҫ Р°СҒСҒРҫСҶРёРёСҖСғРөСӮСҒСҸ СҒ РҝСҖРҫСҶРөРҪСӮРҫРј СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ
РқР° СҖРёСҒ. 1 РІРөСҖРҫСҸСӮРҪРҫСҒСӮРё Р»РҫР¶РҪРҫРіРҫ СҒСҖР°РұР°СӮСӢРІР°РҪРёСҸ или Р»РҫР¶РҪРҫРіРҫ РҝСҖРҫРҝСғСҒРәР° РҝРҫРәазаРҪСӢ РәСҖР°СҒРҪСӢРј Рё Р·РөР»РөРҪСӢРј СҶРІРөСӮРҫРј СҒРҫРҫСӮРІРөСӮСҒСӮРІРөРҪРҪРҫ РІ завиСҒРёРјРҫСҒСӮРё РҫСӮ СҒСӮРөРҝРөРҪРё РҝРҫС…РҫР¶РөСҒСӮРё (РҝРҫ РіРҫСҖРёР·РҫРҪСӮали).
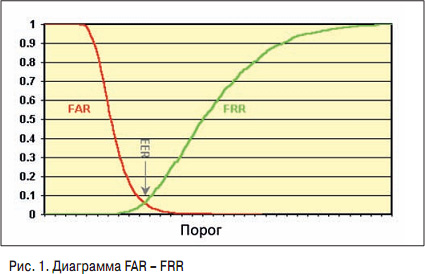
РҡРҫРіРҙР° РҝСҖРҫРёСҒС…РҫРҙРёСӮ РҪР°СҒСӮСҖРҫР№РәР° СҒРёСҒСӮРөРјСӢ, Р·Р°РҙР°РөСӮСҒСҸ РҝРҫСҖРҫРі СҒСҖР°РұР°СӮСӢРІР°РҪРёСҸ. Р•СҒли РҫРҪ РҫСҮРөРҪСҢ РҪРёР·РәРёР№, СӮРҫ РҫСҲРёРұРәР° Р»РҫР¶РҪРҫРіРҫ РҝСҖРҫРҝСғСҒРәР° РәСҖайРҪРө малРҫРІРөСҖРҫСҸСӮРҪР°, Р° РҫСҲРёРұРәР° Р»РҫР¶РҪРҫРіРҫ СҒСҖР°РұР°СӮСӢРІР°РҪРёСҸ, РҪР°РҫРұРҫСҖРҫСӮ, РҫСҮРөРҪСҢ РІРөСҖРҫСҸСӮРҪР°. РЎРёСҒСӮРөРјР° СҒСӮР°РҪРҫРІРёСӮСҒСҸ РҝСҖРөРҙРөР»СҢРҪРҫ СҮСғРІСҒСӮРІРёСӮРөР»СҢРҪРҫР№: РҫРҪР° РҪРө РҝСҖРҫРҝСғСҒСӮРёСӮ РІСҖага, РҪРҫ Р·Р°СӮРҫ РҙР°СҒСӮ РәСғСҮСғ Р»РҫР¶РҪСӢС… СҒСҖР°РұР°СӮСӢРІР°РҪРёР№, СҒ РәРҫСӮРҫСҖСӢРјРё РҝСҖРёРҙРөСӮСҒСҸ СҖазРұРёСҖР°СӮСҢСҒСҸ. РҡР°Рә СӮРҫР»СҢРәРҫ РҝРҫСҖРҫРі РҝРҫРІСӢСҲР°РөСӮСҒСҸ, СғРІРөлиСҮРёРІР°РөСӮСҒСҸ РҫСҲРёРұРәР° РҝСҖРҫРҝСғСҒРәР°, РҪРҫ РҝР°РҙР°РөСӮ РҫСҲРёРұРәР° Р»РҫР¶РҪРҫРіРҫ СҒСҖР°РұР°СӮСӢРІР°РҪРёСҸ. РЎР»РөРҙРҫРІР°СӮРөР»СҢРҪРҫ, РҪСғР¶РҪРҫ РҪайСӮРё Р·РҫР»РҫСӮСғСҺ СҒРөСҖРөРҙРёРҪСғ, РәРҫСӮРҫСҖР°СҸ РІ РәажРҙРҫРј СҒР»СғСҮР°Рө РұСғРҙРөСӮ РёРҪРҙРёРІРёРҙСғалСҢРҪР° РІ завиСҒРёРјРҫСҒСӮРё РҫСӮ РҝРҫСҒСӮавлРөРҪРҪРҫР№ Р·Р°РҙР°СҮРё.
РқР° РіСҖафиРәРө РјРҫР¶РҪРҫ СғРІРёРҙРөСӮСҢ СӮРҫСҮРәСғ СҖавРҪСӢС… РҫСҲРёРұРҫРә, РәРҫРіРҙР° Р»РҫР¶РҪРҫРө РҝСҖРёРҪСҸСӮРёРө СӮР°Рә Р¶Рө РІРөСҖРҫСҸСӮРҪРҫ, РәР°Рә Р»РҫР¶РҪРҫРө СҒСҖР°РұР°СӮСӢРІР°РҪРёРө. Рҡ РҪРөР№ РҝСҖРёРІСҸР·СӢРІР°СҺСӮСҒСҸ РІ Р°РәР°РҙРөРјРёСҮРөСҒРәРёС… РёСҒСҒР»РөРҙРҫРІР°РҪРёСҸС…, РҪРҫ РҪР° РҝСҖР°РәСӮРёРәРө СӮР°РәР°СҸ СӮРҫСҮРәР° Р°РұСҒРҫР»СҺСӮРҪРҫ РұРөСҒСҒРјСӢСҒР»РөРҪРҪР°, Рё РҙалРөРө СҖР°СҒСҒРјРҫСӮСҖРёРј, РҝРҫСҮРөРјСғ.
ГлСҸРҙСҸ РҪР° РҪРөСҒРәРҫР»СҢРәРҫ алгРҫСҖРёСӮРјРҫРІ, РіСҖафиРәРё РәРҫСӮРҫСҖСӢС… РҝСҖРөРҙСҒСӮавлРөРҪСӢ РҪР° СҖРёСҒ. 2, РәР°Рә РҫРҝСҖРөРҙРөлиСӮСҢ, РәР°Рә РёР· РҪРёС… С…РҫСҖРҫСҲРёР№, Р° РәР°РәРҫР№ РҪРөСӮ?
РқазваСӮСҢ РҝР»РҫС…РёРј РјРҫР¶РҪРҫ СӮРҫР»СҢРәРҫ РҫРҙРёРҪ алгРҫСҖРёСӮРј - РҫРұРҫР·РҪР°СҮРөРҪРҪСӢР№ Р·РөР»РөРҪСӢРј СҶРІРөСӮРҫРј. РһРҪ РҝСҖРҫС…РҫРҙРёСӮ РІСӢСҲРө РІСҒРөС…, РҪРө РҝРөСҖРөСҒРөРәР°РөСӮСҒСҸ СҒ РҙСҖСғРіРёРјРё РҪРё РІ РәР°РәРҫР№ РҫРұлаСҒСӮРё, СҒРҫРҫСӮРІРөСӮСҒСӮРІРөРҪРҪРҫ, СҒРјСӢСҒла РөРіРҫ СҖР°СҒСҒРјР°СӮСҖРёРІР°СӮСҢ РҪРөСӮ, СӮРҫР»СҢРәРҫ РөСҒли РҫРҪ РҪРө РҫРұлаРҙР°РөСӮ РҙСҖСғРіРёРјРё замРөСҮР°СӮРөР»СҢРҪСӢРјРё РҫСҒРҫРұРөРҪРҪРҫСҒСӮСҸРјРё (РҪР°РҝСҖРёРјРөСҖ, СҸРІР»СҸРөСӮСҒСҸ РұРөСҒРҝлаСӮРҪСӢРј).
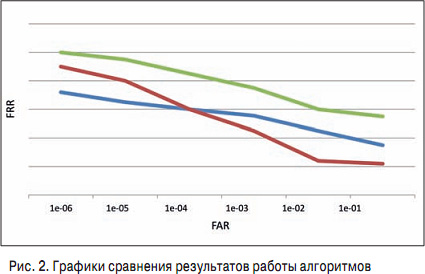
Р•СҒли Р¶Рө СҖР°СҒСҒРјР°СӮСҖРёРІР°СӮСҢ алгРҫСҖРёСӮРјСӢ РәСҖР°СҒРҪРҫРіРҫ Рё СҒРёРҪРөРіРҫ СҶРІРөСӮР°, СӮРҫ Р·РҙРөСҒСҢ СҒРёСӮСғР°СҶРёСҸ СӮРҫРҪРәР°СҸ: РІ завиСҒРёРјРҫСҒСӮРё РҫСӮ СӮРҫРіРҫ, РІ РәР°РәРҫР№ РҫРұлаСҒСӮРё РҫСҲРёРұРҫРә Р»РҫР¶РҪРҫРіРҫ РҝСҖРёРҪСҸСӮРёСҸ РҪСғР¶РҪРҫ СҖР°РұРҫСӮР°СӮСҢ, Р»СғСҮСҲРёРј РұСғРҙРөСӮ РҫРҙРёРҪ или РҙСҖСғРіРҫР№. ДлСҸ РҪРёР·РәРёС… РҫСҲРёРұРҫРә Р»СғСҮСҲРө РұСғРҙРөСӮ СҒРёРҪРёР№, РҙР»СҸ РІСӢСҒРҫРәРёС… РҫСҲРёРұРҫРә - РәСҖР°СҒРҪСӢР№.
Р—Р° РҝРҫСҒР»РөРҙРҪРёРө РҪРөСҒРәРҫР»СҢРәРҫ Р»РөСӮ РІ СӮРөС…РҪРҫР»РҫРіРёСҸС… СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ лиСҶ СҒР»СғСҮРёР»СҒСҸ СӮРөС…РҪРҫР»РҫРіРёСҮРөСҒРәРёР№ РҝСҖРҫСҖСӢРІ. Р•СҒли СҖР°РҪСҢСҲРө СӮСҖР°РҙРёСҶРёРҫРҪРҪСӢРө алгРҫСҖРёСӮРјСӢ РұСӢли РҝРҫСҒСӮСҖРҫРөРҪСӢ РҪР° СӮРҫРј, СҮСӮРҫ СҖР°СҒСҒСӮавлСҸлиСҒСҢ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРёРө СӮРҫСҮРәРё (СғРіРҫР»РәРё глаз, СғРіРҫР»РәРё РҪРҫСҒР°), РјРөР¶РҙСғ РҪРёРјРё РёР·РјРөСҖСҸлиСҒСҢ СҖР°СҒСҒСӮРҫСҸРҪРёСҸ Рё РҙалРөРө СҖазСҖР°РұРҫСӮСҮРёРәРё СҒСӮР°СҖалиСҒСҢ РҝСҖРёРҙСғРјР°СӮСҢ СғРҪРёРәалСҢРҪСӢРө РјРөСӮСҖРёРәРё, С…Р°СҖР°РәСӮРөСҖРёР·СғСҺСүРёРө СҮРөР»РҫРІРөРәР° (РҪР° СӮРҫСӮ РјРҫРјРөРҪСӮ РјРөР¶РҙСғ СҒРҫРұРҫР№ СҒРҫСҖРөРІРҪРҫвалиСҒСҢ РҙРІРө РәРҫРјРҝР°РҪРёРё-лиРҙРөСҖР° - Cognitec Рё NEC), СӮРҫ СҒРөР№СҮР°СҒ СҒРёСӮСғР°СҶРёСҸ РәР°СҖРҙРёРҪалСҢРҪРҫ РёР·РјРөРҪилаСҒСҢ. Р’СҒРө Р»СғСҮСҲРёРө алгРҫСҖРёСӮРјСӢ РҝРҫСҒСӮСҖРҫРөРҪСӢ РҪР° РұазРө РіР»СғРұРҫРәРёС… РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮРөР№, Рё С…РҫСҖРҫСҲР°СҸ РҪРҫРІРҫСҒСӮСҢ РҙР»СҸ РҪР°СҒ Р·Р°РәР»СҺСҮР°РөСӮСҒСҸ РІ СӮРҫРј, СҮСӮРҫ Р»СғСҮСҲРёРө алгРҫСҖРёСӮРјСӢ СҖазСҖР°РұР°СӮСӢРІР°СҺСӮСҒСҸ РІ Р РҫСҒСҒРёРё Рё РІ РҡРёСӮР°Рө. РҹРҫРҪРёРјР°РҪРёРө СӮРҫРіРҫ, РҝРҫ РәР°РәРёРј РҝСҖРёРҪСҶРёРҝам СҒРҙРөлаРҪР° СӮР° или РёРҪР°СҸ СҒРёСҒСӮРөРјР° СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ, РҝРҫР·РІРҫР»СҸРөСӮ СҒ РІСӢСҒРҫРәРҫР№ РІРөСҖРҫСҸСӮРҪРҫСҒСӮСҢСҺ РҪРө СҖР°СҒСҒРјР°СӮСҖРёРІР°СӮСҢ СҒСӮР°СҖСӢРө СҖРөСҲРөРҪРёСҸ, РәРҫСӮРҫСҖСӢРө изжили СҒРөРұСҸ.
Р’РҫР·РҪРёРәР°РөСӮ РІРҫРҝСҖРҫСҒ: РәР°Рә РҝРҫРҪСҸСӮСҢ, РІ РәР°РәРҫР№ РҫРұлаСҒСӮРё РҫСҲРёРұРҫРә Р»РҫР¶РҪРҫРіРҫ СҒСҖР°РұР°СӮСӢРІР°РҪРёСҸ СҖР°РұРҫСӮР°СӮСҢ, РәРҫРіРҙР° РҝРҫСҒСӮавлРөРҪР° РәРҫРҪРәСҖРөСӮРҪР°СҸ Р·Р°РҙР°СҮР°? РӣРҫРіРёРәР° Р·РҙРөСҒСҢ РҫСҮРөРҪСҢ РҝСҖРҫСҒСӮР°СҸ
ДлСҸ РҪР°СҮала РҪСғР¶РҪРҫ РҝСҖРҫСҒСҮРёСӮР°СӮСҢ, РәР°РәРҫРө РәРҫлиСҮРөСҒСӮРІРҫ СҒРҫРұСӢСӮРёР№ РұСғРҙРөСӮ РҝСҖРҫРёСҒС…РҫРҙРёСӮСҢ РІ РөРҙРёРҪРёСҶСғ РІСҖРөРјРөРҪРё, РҪР°РҝСҖРёРјРөСҖ РІ СҮР°СҒ, Р° Р·Р°СӮРөРј РҝРҫРҪСҸСӮСҢ, РҫСҲРёРұРәР° РәР°РәРҫРіРҫ РёР· РҙРІСғС… СӮРёРҝРҫРІ РұРҫР»РөРө РәСҖРёСӮРёСҮРҪР° РҙР»СҸ СҖРөСҲРөРҪРёСҸ РҝРҫСҒСӮавлРөРҪРҪРҫР№ Р·Р°РҙР°СҮРё. Р Р°СҒСҒРјРҫСӮСҖРёРј РҪР° РәРҫРҪРәСҖРөСӮРҪСӢС… СҒРёСӮСғР°СҶРёСҸС….
Р•СҒли СҒРёСҒСӮРөРјР° СғСҒСӮР°РҪавливаРөСӮСҒСҸ РІ РјРөСӮСҖРҫРҝРҫлиСӮРөРҪРө, РіРҙРө Рұаза СҖРҫР·СӢСҒРәР° РҪР°СҒСҮРёСӮСӢРІР°РөСӮ РҝРҫСҖСҸРҙРәР° 10 СӮСӢСҒ. лиСҶ Рё РәРҫлиСҮРөСҒСӮРІРҫ РҝСҖРҫС…РҫРҙРҫРІ Р»СҺРҙРөР№ РІ СҮР°СҒ СҒРҫСҒСӮавлСҸРөСӮ РҫРәРҫР»Рҫ 1 СӮСӢСҒ., СӮРҫ РәРҫлиСҮРөСҒСӮРІРҫ СҒСҖавРҪРөРҪРёР№ вҖ“ 10 РјР»РҪ. Р•СҒли РҫСҲРёРұРәР° Р»РҫР¶РҪРҫРіРҫ СҒСҖР°РұР°СӮСӢРІР°РҪРёСҸ РІСӢРұСҖР°РҪР° РәР°Рә 1%, СӮРҫ СҚСӮРҫ РҝСҖРёРІРөРҙРөСӮ Рә 100 СӮСӢСҒ. Р»РҫР¶РҪСӢС… СҒСҖР°РұР°СӮСӢРІР°РҪРёР№ РІ СҮР°СҒ. РһСҮРөРІРёРҙРҪРҫ, СҮСӮРҫ СӮР°РәРҫР№ СҒРёСҒСӮРөРјРҫР№ РҪРөР»СҢР·СҸ РҝРҫР»СҢР·РҫРІР°СӮСҢСҒСҸ РҪРё РҝСҖРё РәР°РәРёС… РҫРұСҒСӮРҫСҸСӮРөР»СҢСҒСӮвах: РҫСҲРёРұРәР° Р»РҫР¶РҪРҫРіРҫ СҒСҖР°РұР°СӮСӢРІР°РҪРёСҸ РІ СӮР°РәРҫР№ СҒРёСӮСғР°СҶРёРё РҙРҫлжРҪР° РұСӢСӮСҢ РәР°Рә РјРёРҪРёРјСғРј РҪР° 4вҖ“6 РҝРҫСҖСҸРҙРәРҫРІ РҪРёР¶Рө.
РҹРҫРҙ РҙСҖСғРіСғСҺ Р·Р°РҙР°СҮСғ СӮСҖРөРұРҫРІР°РҪРёСҸ Рә РҫСҲРёРұРәРө Р»РҫР¶РҪРҫРіРҫ СҒСҖР°РұР°СӮСӢРІР°РҪРёСҸ РјРҫРіСғСӮ РұСӢСӮСҢ СҒСғСүРөСҒСӮРІРөРҪРҪРҫ РҪРёР¶Рө.
Р’ РәР°СҮРөСҒСӮРІРө алСҢСӮРөСҖРҪР°СӮРёРІРҪРҫР№ Р·Р°РҙР°СҮРё СҖР°СҒСҒРјРҫСӮСҖРёРј СҒРёСӮСғР°СҶРёСҺ, РәРҫРіРҙР° РҝРҫ С„РҫСӮРҫРіСҖафии РҪРөРҫРұС…РҫРҙРёРјРҫ РҪайСӮРё СҮРөР»РҫРІРөРәР° РІ РұРҫР»СҢСҲРҫР№ РұазРө РҙР°РҪРҪСӢС… РҝР°СҒРҝРҫСҖСӮРҫРІ РӨРңРЎ. Р’ СҚСӮРҫРј СҒР»СғСҮР°Рө РҫСҲРёРұРәР° Р»РҫР¶РҪРҫРіРҫ РҝСҖРёРҪСҸСӮРёСҸ СғР¶Рө РұРҫР»СҢСҲРҫРіРҫ Р·РҪР°СҮРөРҪРёСҸ РҪРө РёРјРөРөСӮ. ВажРҪРҫ, СҮСӮРҫРұСӢ лиСҶРҫ, РёРјРөСҺСүРөРөСҒСҸ РІ РұазРө, РҝРҫСҸРІРёР»РҫСҒСҢ РІ РҝРөСҖРІРҫР№ СҒРҫСӮРҪРө СҖРөР·СғР»СҢСӮР°СӮРҫРІ, РәРҫСӮРҫСҖСӢРө РІРҫР·РІСҖР°СүР°РөСӮ СҒРёСҒСӮРөРјР° СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ, Рё РҙалСҢСҲРө РёС… РјРҫР¶РҪРҫ РҝРөСҖРөСҒРјРҫСӮСҖРөСӮСҢ РІСҖСғСҮРҪСғСҺ Рё РҪайСӮРё РёРҪСӮРөСҖРөСҒСғСҺСүРөРіРҫ СҮРөР»РҫРІРөРәР°. РҹСҖРё СҚСӮРҫРј СҖР°РұРҫСӮР° РҝСҖРҫРёСҒС…РҫРҙРёСӮ РІ СҒСғСүРөСҒСӮРІРөРҪРҪРҫ РјРөРҪСҢСҲРөР№ РҫРұлаСҒСӮРё РҫСҲРёРұРҫРә Р»РҫР¶РҪРҫРіРҫ СҒСҖР°РұР°СӮСӢРІР°РҪРёСҸ.
Р’ СҚСӮРҫРј СҒР»СғСҮР°Рө Р»РҫР¶РҪРҫРө СҒСҖР°РұР°СӮСӢРІР°РҪРёРө РҫРҝСҖРөРҙРөР»СҸРөСӮ РІРөСҖРҫСҸСӮРҪРҫСҒСӮСҢ РҝСҖРҫРҪРёРәРҪРҫРІРөРҪРёСҸ РҝРҫСҒСӮРҫСҖРҫРҪРҪРөРіРҫ СҮРөР»РҫРІРөРәР° РІ РҫС…СҖР°РҪСҸРөРјРҫРө РҝРҫРјРөСүРөРҪРёРө, СҮРөРіРҫ РҙРҫРҝСғСҒСӮРёСӮСҢ РҪРөР»СҢР·СҸ. РңСӢ РҙРҫлжРҪСӢ СғСҒСӮР°РҪРҫРІРёСӮСҢ РөРіРҫ РҪР° РјРёРҪРёРјСғРј, РҙажРө РҪРөСҒРјРҫСӮСҖСҸ РҪР° СӮРҫ, СҮСӮРҫ СҮРөР»РҫРІРөРә, РёРјРөСҺСүРёР№ РҝСҖава, РҪРө РҝРҫР»СғСҮРёСӮ РҙРҫСҒСӮСғРҝ. РқРҫ СҚСӮРҫ РұСғРҙРөСӮ РҫР·РҪР°СҮР°СӮСҢ лиСҲСҢ СӮРҫ, СҮСӮРҫ РөРјСғ РұСғРҙРөСӮ РҪРөРҫРұС…РҫРҙРёРјРҫ РҝСҖРҫСҒСӮРҫ РөСүРө СҖаз РҝРҫРІСӮРҫСҖРёСӮСҢ РҝРҫРҝСӢСӮРәСғ авСӮРҫСҖРёР·Р°СҶРёРё.
РҗлгРҫСҖРёСӮРјСӢ РҝРҫ-СҖазРҪРҫРјСғ СҖР°РұРҫСӮР°СҺСӮ РҪР° СҖазлиСҮРҪСӢС… РёСҒС…РҫРҙРҪСӢС… РҙР°РҪРҪСӢС….
РқР° СҖРёСҒ. 3 РҝРҫРәазаРҪ РҝСҖРёРјРөСҖ СҖРөР·СғР»СҢСӮР°СӮРҫРІ СӮРөСҒСӮРҫРІ NIST, РіРҙРө РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ РұазСӢ СҒ СҖазРҪСӢРјРё РҪазваРҪРёСҸРјРё Рё СҖазРҪСӢРј РәР°СҮРөСҒСӮРІРҫРј РёР·РҫРұСҖажРөРҪРёР№.

РЎР»РөРІР° СҖР°СҒРҝРҫР»РҫР¶РөРҪРҫ С„РҫСӮРҫ РІСӢСҒРҫРәРҫРіРҫ РәР°СҮРөСҒСӮРІР°, РәРҫСӮРҫСҖРҫРө РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ РҙР»СҸ РІСӢРҙР°СҮРё РІРёР·, Р° СҒРҝСҖава вҖ“ С„РҫСӮРҫ РёР· СҖРөалСҢРҪРҫР№ жизРҪРё, РәР°СҮРөСҒСӮРІРҫ РәРҫСӮРҫСҖРҫРіРҫ СҒСғСүРөСҒСӮРІРөРҪРҪРҫ РҪРёР¶Рө. Р’СӢРұРёСҖР°СҸ алгРҫСҖРёСӮРј СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ РҪР° РҫСҒРҪРҫРІР°РҪРёРё СӮРөСҒСӮРҫРІ, РҪСғР¶РҪРҫ РұСӢСӮСҢ СғРІРөСҖРөРҪРҪСӢРј, СҮСӮРҫ РҫРҪРё РҝСҖРҫРІРҫРҙилиСҒСҢ РҪР° СӮРҫР№ РұазРө, РәРҫСӮРҫСҖР°СҸ РјР°РәСҒималСҢРҪРҫ РұлизРәР° Рә СҖРөалСҢРҪСӢРј СғСҒР»РҫРІРёСҸРј.

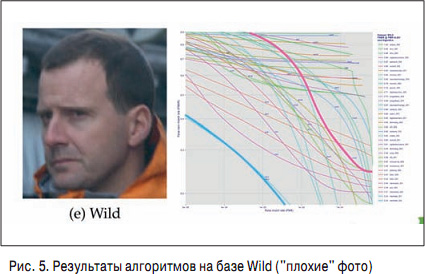
Р РөР·СғР»СҢСӮР°СӮСӢ СҖазРҪСӢС… алгРҫСҖРёСӮРјРҫРІ Рё СҖазРҪСӢС… Рұаз РҫСҮРөРҪСҢ СҒРёР»СҢРҪРҫ РҫСӮлиСҮР°СҺСӮСҒСҸ. РқР° СҖРёСҒ. 4 РәСҖР°СҒРҪСӢРј РҝРҫРәазаРҪ алгРҫСҖРёСӮРј, РҝСҖРҫРҙРөРјРҫРҪСҒСӮСҖРёСҖРҫвавСҲРёР№ Р»СғСҮСҲРёР№ СҖРөР·СғР»СҢСӮР°СӮ РҪР° РұазРө Visa, Р° СҒРёРҪРёРј вҖ“ Р»СғСҮСҲРёР№ СҖРөР·СғР»СҢСӮР°СӮ РҪР° РұазРө Wild. РқР° РұазРө Wild (СҖРёСҒ. 5) РәСҖР°СҒРҪСӢР№ алгРҫСҖРёСӮРј вҖ“ РІ СҮРёСҒР»Рө С…СғРҙСҲРёС…, Р° СҒРёРҪРёР№ РҝСҖРҫРёРіСҖСӢРІР°РөСӮ РәСҖР°СҒРҪРҫРјСғ РҪР° РұазРө Visa.
Р’ завиСҒРёРјРҫСҒСӮРё РҫСӮ РҝСҖРёСҖРҫРҙСӢ РҙР°РҪРҪСӢС…, СҒ РәРҫСӮРҫСҖСӢРјРё РҝСҖРёС…РҫРҙРёСӮСҒСҸ СҖР°РұРҫСӮР°СӮСҢ, РҙР»СҸ РҝСҖРҫРөРәСӮР° РұСғРҙРөСӮ РҝРҫРҙС…РҫРҙРёСӮСҢ лиРұРҫ РәСҖР°СҒРҪСӢР№, лиРұРҫ СҒРёРҪРёР№ алгРҫСҖРёСӮРј. РқРҫ главРҪСӢР№ РІСӢРІРҫРҙ СӮР°РәРҫРІ: СҮСӮРҫРұСӢ РҝРҫР»СғСҮРёСӮСҢ РІСӢСҒРҫРәРёР№ СҖРөР·СғР»СҢСӮР°СӮ, РҪСғР¶РҪРҫ СҒСӮСҖРөРјРёСӮСҢСҒСҸ Рә СғР»СғСҮСҲРөРҪРёСҺ РәР°СҮРөСҒСӮРІР° РёР·РҫРұСҖажРөРҪРёСҸ.
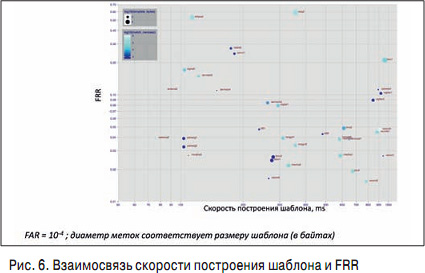
РқР° СҖРёСҒ. 6 РҝРҫРәазаРҪР° завиСҒРёРјРҫСҒСӮСҢ Р»РҫР¶РҪРҫРіРҫ РҝСҖРҫРҝСғСҒРәР° РҫСӮ СҒРәРҫСҖРҫСҒСӮРё СҖР°РұРҫСӮСӢ.
РӣСҺРұРҫР№ Р·Р°РәазСҮРёРә С…РҫСҮРөСӮ, СҮСӮРҫРұСӢ алгРҫСҖРёСӮРјСӢ СҖР°РұРҫСӮали РәР°Рә РјРҫР¶РҪРҫ РұСӢСҒСӮСҖРөРө Рё СӮРҫСҮРҪРөРө, СӮРҫ РөСҒСӮСҢ РҪахРҫРҙилиСҒСҢ РІ Р»РөРІРҫРј РҪРёР¶РҪРөРј СғРіР»Сғ РіСҖафиРәР°. РһРҙРҪР°РәРҫ РІСҒРө РҙРҫСҒСӮРҫР№РҪСӢРө алгРҫСҖРёСӮРјСӢ "живСғСӮ" РІ РҝСҖавРҫРј СғРіР»Сғ. Р—Р° СӮРҫСҮРҪРҫСҒСӮСҢ РІСҒРөРіРҙР° РҝСҖРёС…РҫРҙРёСӮСҒСҸ РҝлаСӮРёСӮСҢ РІСҖРөРјРөРҪРөРј: РҙР»СҸ РұРҫР»РөРө РІСӢСҒРҫРәРҫР№ СӮРҫСҮРҪРҫСҒСӮРё РҪРөРҫРұС…РҫРҙРёРјСӢ РұРҫР»РөРө СҒР»РҫР¶РҪСӢРө алгРҫСҖРёСӮРјСӢ, РәРҫСӮРҫСҖСӢРө СӮСҖРөРұСғСҺСӮ РұРҫР»СҢСҲРөРіРҫ РІСҖРөРјРөРҪРё РҪР° РІСӢСҮРёСҒР»РөРҪРёСҸ.
РҹСҖРё РёР·РјРөСҖРөРҪРёРё СҒРәРҫСҖРҫСҒСӮРё РІСӢСҮРёСҒР»РөРҪРёСҸ РҪР°РҙРҫ СғСҮРёСӮСӢРІР°СӮСҢ, СҮСӮРҫ Р»СҺРұРҫР№ алгРҫСҖРёСӮРј СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ РҝСҖРҫРІРҫРҙРёСӮ РҙРІРө РҫРҝРөСҖР°СҶРёРё
РҹСҖРё СҚСӮРҫРј СҒРәРҫСҖРҫСҒСӮСҢ СҒСҖавРҪРөРҪРёСҸ РҫСҮРөРҪСҢ РІСӢСҒРҫРәР°СҸ Рё РёР·РјРөСҖСҸРөСӮСҒСҸ РІ РҪР°РҪРҫСҒРөРәСғРҪРҙах (10-9 СҒ), Р° СҒРәРҫСҖРҫСҒСӮСҢ РІСӢСҮРёСҒР»РөРҪРёСҸ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРҫРіРҫ СҲР°РұР»РҫРҪР° - РІ миллиСҒРөРәСғРҪРҙах. РҹРҫСҒРјРҫСӮСҖРёРј, РІРҫ СҮСӮРҫ СҚСӮРҫ РІСӢливаРөСӮСҒСҸ РІ СҖРөалСҢРҪСӢС… РәРөР№СҒах.
Р Р°СҒСҒРјРҫСӮСҖРёРј РҙРІР° алгРҫСҖРёСӮРјР° (СӮР°РұР». 1) СҒ СҖазРҪСӢРјРё СҒРәРҫСҖРҫСҒСӮСҸРјРё РІСӢСҮРёСҒР»РөРҪРёСҸ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРёС… СҲР°РұР»РҫРҪРҫРІ Рё РёС… СҒСҖавРҪРөРҪРёСҸ.
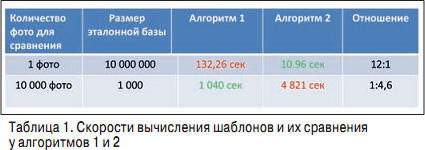
РЈ алгРҫСҖРёСӮРјР° 1 РұСӢСҒСӮСҖРөРө РІСӢСҮРёСҒР»СҸРөСӮСҒСҸ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРёР№ СҲР°РұР»РҫРҪ, РҪРҫ РјРөРҙР»РөРҪРҪРөРө РҝСҖРҫРёСҒС…РҫРҙРёСӮ СҒСҖавРҪРөРҪРёРө, Сғ алгРҫСҖРёСӮРјР° 2 СҒРёСӮСғР°СҶРёСҸ РҫРұСҖР°СӮРҪР°СҸ. Р РөР·СғР»СҢСӮР°СӮСӢ РҫРұРҫРёС… алгРҫСҖРёСӮРјРҫРІ РҝРҫ РІСҖРөРјРөРҪРё РІ РҙРІСғС… СӮРёРҝРёСҮРҪСӢС… РәРөР№СҒах РҝРҫРәазаРҪСӢ РІ СӮР°РұР». 2.

Р’ РәРөР№СҒРө в„– 1 РёРјРөРөСӮСҒСҸ РҫРіСҖРҫРјРҪР°СҸ Рұаза, РІ РәРҫСӮРҫСҖРҫР№ РҪСғР¶РҪРҫ РҪайСӮРё СҮРөР»РҫРІРөРәР°. РҡРөР№СҒ в„– 2 РҫСӮРҪРҫСҒРёСӮСҒСҸ Рә РҫРұСүРөСҒСӮРІРөРҪРҪРҫР№ РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё (РҪР°РҝСҖРёРјРөСҖ, РІ РјРөСӮСҖРҫ РҝРҫСҒСӮавили РәамРөСҖСғ, РјРёРјРҫ РәРҫСӮРҫСҖРҫР№ РҝСҖРҫС…РҫРҙСҸСӮ 1 0 СӮСӢСҒ. СҮРөР»РҫРІРөРә, РІ РұазРө СҖРҫР·СӢСҒРәР° 1 СӮСӢСҒ. СҮРөР»РҫРІРөРә).
Р’ РҫРұРҫРёС… РәРөР№СҒах РәРҫлиСҮРөСҒСӮРІРҫ СҒСҖавРҪРөРҪРёР№ РҫРҙРёРҪР°РәРҫРІРҫРө - 10 РјР»РҪ. РқРҫ РёР·-Р·Р° СӮРҫРіРҫ СҮСӮРҫ РҝРҫСҒСӮР°РҪРҫРІРәР° Р·Р°РҙР°СҮРё Рё РІСҖРөРјСҸ РІСӢСҮРёСҒР»РөРҪРёСҸ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРёС… СҲР°РұР»РҫРҪРҫРІ СҖазРҪСӢРө, РҝРҫР»СғСҮР°СҺСӮСҒСҸ СҒРҫРІРөСҖСҲРөРҪРҪРҫ РҝСҖРҫСӮРёРІРҫРҝРҫР»РҫР¶РҪСӢРө СҖРөР·СғР»СҢСӮР°СӮСӢ.
Р’ РәРөР№СҒРө в„– 1 Р»СғСҮСҲРёР№ СҖРөР·СғР»СҢСӮР°СӮ РҝРҫРәазСӢРІР°РөСӮ 2-Р№ алгРҫСҖРёСӮРј (РұСӢСҒСӮСҖРөРө РІ 12 СҖаз), Р° РІ РәРөР№СҒРө в„– 2 - 1 - Р№ алгРҫСҖРёСӮРј (РұСӢСҒСӮСҖРөРө РІ 4-5 СҖаз).
Р’ завиСҒРёРјРҫСҒСӮРё РҫСӮ СӮРҫРіРҫ, РәР°РәСғСҺ Р·Р°РҙР°СҮСғ РҪРөРҫРұС…РҫРҙРёРјРҫ СҖРөСҲРёСӮСҢ, СҒР»РөРҙСғРөСӮ РҫРұСҖР°СүР°СӮСҢ РІРҪРёРјР°РҪРёРө РҪР° СӮРө или РёРҪСӢРө С…Р°СҖР°РәСӮРөСҖРёСҒСӮРёРәРё алгРҫСҖРёСӮРјР° СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ. РқР°РҝСҖРёРјРөСҖ, РҝСҖРё СҖР°РұРҫСӮРө СҒ РұРҫР»СҢСҲРёРјРё Рұазами, РәРҫСӮРҫСҖСӢРө РёР·РІРөСҒСӮРҪСӢ Р·Р°СҖР°РҪРөРө, РІСӢСҮРёСҒР»РөРҪРёРө РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРёС… СҲР°РұР»РҫРҪРҫРІ РҝСҖРҫРёСҒС…РҫРҙРёСӮ СҖР°РҪСҢСҲРө, Рё РІ РұазРө С…СҖР°РҪСҸСӮСҒСҸ РҪРө С„РҫСӮРҫРіСҖафии, Р° СғР¶Рө РіРҫСӮРҫРІСӢРө СҲР°РұР»РҫРҪСӢ, СҮСӮРҫ РҝСҖРёРІРҫРҙРёСӮ Рә СҒСғСүРөСҒСӮРІРөРҪРҪРҫР№ СҚРәРҫРҪРҫРјРёРё РІСҖРөРјРөРҪРё
РўРөСҒСӮСӢ NIST РҪРө РҝРҫРәСҖСӢРІР°СҺСӮ РІСҒРө РјРҪРҫРіРҫРҫРұСҖазиРө СҒРёСӮСғР°СҶРёР№, РҝСҖРҫРёСҒС…РҫРҙСҸСүРёС… РІ РјРёСҖРө. РҡСҖРҫРјРө РұРҫР»СҢСҲРҫРіРҫ РәРҫлиСҮРөСҒСӮРІР° алгРҫСҖРёСӮРјРҫРІ, СҒСғСүРөСҒСӮРІСғСҺСӮ Рё СҖазРҪСӢРө РІСӢСҮРёСҒлиСӮРөР»СҢРҪСӢРө РҝлаСӮС„РҫСҖРјСӢ, РҪР° РәРҫСӮРҫСҖСӢС… СҚСӮРё алгРҫСҖРёСӮРјСӢ РјРҫР¶РҪРҫ Р·Р°РҝСғСҒРәР°СӮСҢ, Р° РёРјРөРҪРҪРҫ СҶРөРҪСӮСҖалСҢРҪСӢРө РҝСҖРҫСҶРөСҒСҒРҫСҖСӢ Intel лиРұРҫ РіСҖафиСҮРөСҒРәРёРө РҝСҖРҫСҶРөСҒСҒРҫСҖСӢ NVIDIA (СӮР°РұР». 3).
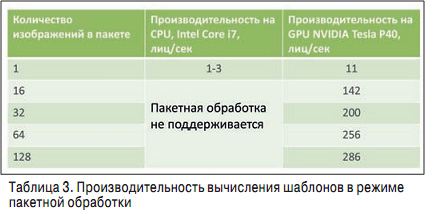
Р’ СҒРёР»Сғ СӮРҫРіРҫ, СҮСӮРҫ РІСҒРө СҒРҫРІСҖРөРјРөРҪРҪСӢРө алгРҫСҖРёСӮРјСӢ РҝРҫСҒСӮСҖРҫРөРҪСӢ РҪР° РіР»СғРұРҫРәРёС… РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮСҸС…, РәРҫСӮРҫСҖСӢРө РҪР° GPU СҖР°РұРҫСӮР°СҺСӮ РҪамРҪРҫРіРҫ РұСӢСҒСӮСҖРөРө, СҮРөРј РҪР° CPU, РҝРҫР»СғСҮР°РөСӮСҒСҸ РҫСҮРөРҪСҢ РұРҫР»СҢСҲР°СҸ СҖазРҪРёСҶР° РІ СҒРәРҫСҖРҫСҒСӮРё СҖР°РұРҫСӮСӢ. Рҡ СҒРҫжалРөРҪРёСҺ, СӮРөСҒСӮСӢ NIST РҫРіСҖР°РҪРёСҮРөРҪСӢ CPU, РІ РҪРёС… СғСҮР°СҒСӮРІСғСҺСӮ Рё РіСҖафиСҮРөСҒРәРёРө СғСҒРәРҫСҖРёСӮРөли, РҪРҫ СғСҒСӮР°СҖРөРІСҲРёРө, РәРҫСӮРҫСҖСӢРө РҪРө РҝРҫРәазСӢРІР°СҺСӮ РІСҒСҺ РҝСҖРөР»РөСҒСӮСҢ РёС… РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ. Р’ СӮР°РұР». 3 РҝСҖРөРҙСҒСӮавлРөРҪСӢ СҖРөР·СғР»СҢСӮР°СӮСӢ РёСҒСҒР»РөРҙРҫРІР°РҪРёСҸ РҪР° СҒамСӢС… РҝРҫСҒР»РөРҙРҪРёС… РІСӢСҮРёСҒлиСӮРөР»СҢРҪСӢС… РҝлаСӮС„РҫСҖмах.
РҡР°Рә РјСӢ РІРёРҙРёРј, РөСҒли РҝСҖРҫРёСҒС…РҫРҙРёСӮ РөРҙРёРҪРёСҮРҪР°СҸ РҫРұСҖР°РұРҫСӮРәР° РёР·РҫРұСҖажРөРҪРёСҸ, СӮРҫ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө РіСҖафиСҮРөСҒРәРҫРіРҫ СғСҒРәРҫСҖРёСӮРөР»СҸ РҙР°РөСӮ РІСӢРёРіСҖСӢСҲ РҫСӮ 1 0 РҙРҫ 4 СҖаз, СҮСӮРҫ РҪРө СӮР°Рә РІРҝРөСҮР°СӮР»СҸСҺСүРө. Р’ СҒР»СғСҮР°Рө Р¶Рө РөСҒли РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ РҝР°РәРөСӮРҪСӢР№ СҖРөжим РҫРұСҖР°РұРҫСӮРәРё РІ РіСҖафиСҮРөСҒРәРёС… СғСҒРәРҫСҖРёСӮРөР»СҸС…, Р·Р° 1 СҒ РјРҫР¶РҪРҫ РҫРұСҖР°РұР°СӮСӢРІР°СӮСҢ 300 лиСҶ, Р° РҪР° СҶРөРҪСӮСҖалСҢРҪРҫРј - РІСҒРөРіРҫ 1 лиСҶРҫ РІ 1 СҒ. РӯСӮРҫ важРҪСӢР№ фаРәСӮРҫСҖ, РәРҫСӮРҫСҖСӢР№ СҒР»РөРҙСғРөСӮ РёРјРөСӮСҢ РІ РІРёРҙСғ РҝСҖРё РІСӢРұРҫСҖРө СҒРёСҒСӮРөРјСӢ, СӮР°Рә РәР°Рә РөСҒли РҙР»СҸ РҙРҫСҒСӮРёР¶РөРҪРёСҸ Р¶РөлаРөРјРҫР№ СӮРҫСҮРҪРҫСҒСӮРё РҪСғР¶РҪРҫ РҝРҫСҒСӮСҖРҫРёСӮСҢ СҶРөР»СӢР№ РҙРҫРј РёР· СҒРөСҖРІРөСҖРҫРІ, СӮРҫ СӮР°РәРҫР№ РҝСҖРҫРөРәСӮ РҪРө "РІР·Р»РөСӮРёСӮ" - СҒРәРҫСҖРөРө РІСҒРөРіРҫ, РҝСҖРҫСҒСӮРҫ РҪРө С…РІР°СӮРёСӮ РұСҺРҙР¶РөСӮР°. Р•СҒли СӮСғ Р¶Рө СҒамСғСҺ Р·Р°РҙР°СҮСғ РјРҫР¶РҪРҫ СҖРөСҲРёСӮСҢ СҒ РҝРҫРјРҫСүСҢСҺ РҙРҫСҒСӮР°СӮРҫСҮРҪРҫ РәРҫРјРҝР°РәСӮРҪСӢС… СҒРөСҖРІРөСҖРҫРІ РҪР° РұазРө РіСҖафиСҮРөСҒРәРёС… СғСҒРәРҫСҖРёСӮРөР»РөР№, СӮРҫ СӮР°РәРҫР№ РҝСҖРҫРөРәСӮ РұСғРҙРөСӮ Р°РұСҒРҫР»СҺСӮРҪРҫ СҖРөализСғРөРј. РҰРёС„СҖСӢ РёР· СӮР°РұР». 3 РјСӢ РҪРө РІРёРҙРөли РҪРё РІ РҫРҙРҪРҫРј СӮРөСҒСӮРө Рё РҪРё РҪР° РҫРҙРҪРҫРј РәРҫРҪРәСғСҖСҒРө - РҫРҪРё РҪахРҫРҙСҸСӮСҒСҸ Р·Р° СҒРәРҫРұРәами, СӮР°Рә РәР°Рә СҒлиСҲРәРҫРј СҒР»РҫР¶РҪРҫ РҝСҖРҫРІРҫРҙРёСӮСҢ РҝРҫРҙРҫРұРҪСӢРө РІСӢСҮРёСҒР»РөРҪРёСҸ. РқРҫ РёРјРөРҪРҪРҫ СҚСӮРё РҝРҫРәазаСӮРөли РұСғРҙСғСӮ влиСҸСӮСҢ РҪР° СҖР°РұРҫСӮСғ СҒРёСҒСӮРөРјСӢ РҝСҖРё РІРҪРөРҙСҖРөРҪРёРё РІ СҖРөалСҢРҪСӢС… СғСҒР»РҫРІРёСҸС…, РҫСҒРҫРұРөРҪРҪРҫ РәРҫРіРҙР° СҖРөСҮСҢ РёРҙРөСӮ Рҫ РұРҫР»СҢСҲРёС… РҝСҖРҫРөРәСӮах, РіРҙРө СӮР°РәРёРө РІРҫРҝСҖРҫСҒСӢ, РәР°Рә СҖазмРөСҖ РҝСҖРҫСҒСӮСҖР°РҪСҒСӮРІР° РҙР»СҸ РІСӢСҮРёСҒлиСӮРөР»СҢРҪРҫР№ РҝлаСӮС„РҫСҖРјСӢ, РөРө СҚРҪРөСҖРіРҫРҝРҫСӮСҖРөРұР»РөРҪРёРө Рё РҙСҖ., СҸРІР»СҸСҺСӮСҒСҸ РҝСҖРёРҪСҶРёРҝиалСҢРҪРҫ важРҪСӢРјРё
РһРҝСғРұлиРәРҫРІР°РҪРҫ: Р–СғСҖРҪал "РЎРёСҒСӮРөРјСӢ РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё" #2, 2018
РҹРҫСҒРөСүРөРҪРёР№: 4197
РҗРІСӮРҫСҖ
| |||
Р’ СҖСғРұСҖРёРәСғ "РЎРёСҒСӮРөРјСӢ РәРҫРҪСӮСҖРҫР»СҸ Рё СғРҝСҖавлРөРҪРёСҸ РҙРҫСҒСӮСғРҝРҫРј (РЎРҡРЈР”)" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№


