






Р’ СҖСғРұСҖРёРәСғ "РЎРёСҒСӮРөРјСӢ РәРҫРҪСӮСҖРҫР»СҸ Рё СғРҝСҖавлРөРҪРёСҸ РҙРҫСҒСӮСғРҝРҫРј (РЎРҡРЈР”)" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№

РЎ СӮРҫСҮРәРё Р·СҖРөРҪРёСҸ РҝСҖРёРјРөРҪРөРҪРёСҸ РІ СҒРёСҒСӮРөмах РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё СҒ РҝРҫРІСӢСҲРөРҪРҪСӢРјРё СӮСҖРөРұРҫРІР°РҪРёСҸРјРё Рә СӮРҫСҮРҪРҫСҒСӮРё Рё РҪР°РҙРөР¶РҪРҫСҒСӮРё СҒамСӢРј РҝРөСҖСҒРҝРөРәСӮРёРІРҪСӢРј РјРөСӮРҫРҙРҫРј (РҪРө СҒСҮРёСӮР°СҸ СӮРҫСҮРҪРҫРіРҫ Р°РҪализа Р”РқРҡ) РёРҙРөРҪСӮифиРәР°СҶРёРё СҮРөР»РҫРІРөРәР° СҸРІР»СҸРөСӮСҒСҸ СҖР°СҒРҝРҫР·РҪаваРҪРёРө РҝРҫ СҖР°РҙСғР¶РҪРҫР№ РҫРұРҫР»РҫСҮРәРө глаза. РӯСӮРҫ РҫРұСғСҒР»РҫРІР»РөРҪРҫ СҒР»РөРҙСғСҺСүРёРјРё фаРәСӮРҫСҖами:
1. Р Р°РҙСғР¶РҪР°СҸ РҫРұРҫР»РҫСҮРәР° РҪаиРұРҫР»РөРө РёРҪС„РҫСҖРјР°СӮРёРІРҪР° РёР· РІСҒРөС… СҖазРҪРҫРҫРұСҖазРҪСӢС… РұРёРҫРјРөСӮСҖРёРә. Р”РөР№СҒСӮРІРёСӮРөР»СҢРҪРҫ, СӮРөРҫСҖРөСӮРёСҮРөСҒРәР°СҸ (РҝРҫРҙСҮРөСҖРәРҪРөРј вҖ“ СҮРёСҒСӮРҫ СӮРөРҫСҖРөСӮРёСҮРөСҒРәРё, СҒ СӮРҫСҮРәРё Р·СҖРөРҪРёСҸ РјР°СӮРөРјР°СӮРёРәРё) РІРөСҖРҫСҸСӮРҪРҫСҒСӮСҢ СӮРҫРіРҫ, СҮСӮРҫ РҙРІР° СҖазРҪСӢС… СҮРөР»РҫРІРөРәР° РёРјРөСҺСӮ РҫРҙРёРҪР°РәРҫРІСӢРө СҖРёСҒСғРҪРәРё СҖР°РҙСғР¶РәРё РҪР° СҒРІРҫРёС… РҙРІСғС… глазах, РҝСҖРёРұлизиСӮРөР»СҢРҪРҫ СҖавРҪР° 10-78, РІ СӮРҫ РІСҖРөРјСҸ РәР°Рә РІСҒРө РҪР°СҒРөР»РөРҪРёРө Р—Рөмли СҒРҫСҒСӮавлСҸРөСӮ <1010. РҹРҫРҪСҸСӮРҪРҫРө РҙРөР»Рҫ, СҮСӮРҫ РІ СҖРөалСҢРҪРҫР№ физиСҮРөСҒРәРҫР№ СҒРёСҒСӮРөРјРө РјСӢ РҪРёРәРҫРіРҙР° РҪРө РҙРҫСҒСӮРёРіРҪРөРј Р·РҪР°СҮРөРҪРёР№ 10-78, РҫРҙРҪР°РәРҫ РҙажРө РҝРҫР»СғСҮР°РөРјСӢРө Р·РҪР°СҮРөРҪРёСҸ 10-10вҖ“10-11 РҙР°СҺСӮ С„РҫСҖСғ РІ 4вҖ“6 РҝРҫСҖСҸРҙРәРҫРІ РІСҒРөРј РҙСҖСғРіРёРј РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРёРј РјРөСӮРҫРҙам, РІРәР»СҺСҮР°СҸ РҙРІСғС…РјРҫРҙалСҢРҪСӢРө.
2. РЎСӮР°РұРёР»СҢРҪРҫСҒСӮСҢ РұРёРҫРјРөСӮСҖРёРәРё РҝРҫ СҖР°РҙСғР¶РәРө РІРҫ РІСҖРөРјРөРҪРё.
Р РёСҒСғРҪРҫРә СҖР°РҙСғР¶РәРё С„РҫСҖРјРёСҖСғРөСӮСҒСҸ РҪР° РІРҫСҒСҢРјРҫРј РјРөСҒСҸСҶРө РІРҪСғСӮСҖРёСғСӮСҖРҫРұРҪРҫРіРҫ СҖазвиСӮРёСҸ, РҫРәРҫРҪСҮР°СӮРөР»СҢРҪРҫ СҒСӮР°РұилизиСҖСғРөСӮСҒСҸ РІ РІРҫР·СҖР°СҒСӮРө РҫРәРҫР»Рҫ РҙРІСғС…вҖ“СӮСҖРөС… Р»РөСӮ Рё РҝСҖР°РәСӮРёСҮРөСҒРәРё РҪРө РёР·РјРөРҪСҸРөСӮСҒСҸ РІ СӮРөСҮРөРҪРёРө жизРҪРё, РәСҖРҫРјРө РәР°Рә РІ СҖРөР·СғР»СҢСӮР°СӮРө СҒРёР»СҢРҪСӢС… СӮСҖавм или СҖРөР·РәРёС… РҝР°СӮРҫР»РҫРіРёР№.
3. РқР° СҒРөРіРҫРҙРҪСҸСҲРҪРёР№ РҙРөРҪСҢ РҪРөСӮ СҚРәРҫРҪРҫРјРёСҮРөСҒРәРё РҫРұРҫСҒРҪРҫРІР°РҪРҪСӢС… СҒРҝРҫСҒРҫРұРҫРІ РҝРҫРІСӮРҫСҖРёСӮСҢ/СҒРәРҫРҝРёСҖРҫРІР°СӮСҢ/РҝРҫРҙРҙРөлаСӮСҢ СҖРёСҒСғРҪРҫРә СҖР°РҙСғР¶РәРё Рё РҫРұРјР°РҪСғСӮСҢ СӮР°РәСғСҺ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәСғСҺ СҒРёСҒСӮРөРјСғ. РӯСӮРҫ РҙР°РөСӮ Р·РҪР°СҮРёСӮРөР»СҢРҪРҫРө РҝСҖРөРёРјСғСүРөСҒСӮРІРҫ РІ СҒСҖавРҪРөРҪРёРё СҒ РұРёРҫРјРөСӮСҖРёРөР№ РҝРҫ лиСҶСғ или РҝРҫ РҝалСҢСҶам.
4. РқР°РәРҫРҪРөСҶ, РұРөСҒРәРҫРҪСӮР°РәСӮРҪСӢР№ СҒРҝРҫСҒРҫРұ РҝРҫР»СғСҮРөРҪРёСҸ РёР·РҫРұСҖажРөРҪРёСҸ СҖР°РҙСғР¶РәРё РҙРөлаРөСӮ РҝСҖРёРІР»РөРәР°СӮРөР»СҢРҪСӢРј РөРіРҫ РҝСҖРёРјРөРҪРөРҪРёРө РІ СҖРөалСҢРҪСӢС… РҝСҖРёР»РҫР¶РөРҪРёСҸС….
РҳРҙРөСҸ СҖР°СҒРҝРҫР·РҪаваСӮСҢ Р»СҺРҙРөР№ РҝРҫ СҖР°РҙСғР¶РҪРҫР№ РҫРұРҫР»РҫСҮРәРө глаза РІРҫР·РҪРёРәла Сғ РҝСҖРҫС„РөСҒСҒРҫСҖР° ДжРҫРҪР° Р”РҫСғРіРјР°РҪР° РІ 1987 Рі., РҫРҪ РөРө Р·Р°РҝР°СӮРөРҪСӮРҫвал, Рё РҝР°СӮРөРҪСӮРҪР°СҸ Р·Р°СүРёСӮР° РҪРө Рҙавала РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РәРҫРјСғ-лиРұРҫ СҒРҫР·РҙР°СӮСҢ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРёР№ СҒРәР°РҪРөСҖ РҝРҫ СҖР°РҙСғР¶РәРө. Рҳ лиСҲСҢ Рә 2006-2009 РіРі СҒСӮали РҝРҫСҸРІР»СҸСӮСҢСҒСҸ РҝРөСҖРІСӢРө СғСҒРҝРөСҲРҪСӢРө (Рё РҪРө РҫСҮРөРҪСҢ) РјРҫРҙРөли. РқРҫ СҒСӮРҫРёР»Рҫ РІСҒРө СҚСӮРҫ СҒлиСҲРәРҫРј РҙРҫСҖРҫРіРҫ. РЎ СғСҮРөСӮРҫРј РІРҫР·РјРҫР¶РҪРҫСҒСӮРөР№ СҒРҫРІСҖРөРјРөРҪРҪРҫРіРҫ Р¶РөР»РөР·Р° РјСӢ СғР¶Рө РјРҫР¶РөРј СҒРҫР·РҙаваСӮСҢ РәРҫРјРјРөСҖСҮРөСҒРәРёРө РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРёРө СҒРәР°РҪРөСҖСӢ СҒ СғРәазаРҪРҪСӢРјРё РІСӢСҲРө Р·РҪР°СҮРөРҪРёСҸРјРё РҫСҲРёРұРҫРә.
Р—РҙРөСҒСҢ РёРјРөРөСӮ СҒРјСӢСҒР» СҒРҫРІСҒРөРј РҪРөРјРҪРҫРіРҫ "РҝСҖРҫРұРөжаСӮСҢСҒСҸ" РҝРҫ СӮРөРҫСҖРёРё, РҪРө СғСӮРҫРјР»СҸСҸ СҮРёСӮР°СӮРөР»СҸ РҙРөСӮалСҸРјРё Рё СӮРҫРҪРәРҫСҒСӮСҸРјРё РјР°СӮРөРјР°СӮРёСҮРөСҒРәРҫРіРҫ Р°РҝРҝР°СҖР°СӮР° Рё РёСҒРҝРҫР»СҢР·СғРөРјСӢС… алгРҫСҖРёСӮРјРҫРІ.
РҡлаСҒСҒРёСҮРөСҒРәРёР№ алгРҫСҖРёСӮРј СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ (Сғ СӮРҫРіРҫ Р¶Рө Р”РҫСғРіРјР°РҪР°) СҒРҫСҒСӮРҫРёСӮ РёР· РҙРІСғС… СҮР°СҒСӮРөР№ - СҒРөРіРјРөРҪСӮР°СҶРёРё Рё СҒСҖавРҪРөРҪРёСҸ.
РЎРөРіРјРөРҪСӮР°СҶРёСҸ вҖ“ СҚСӮРҫ РІСӢРҙРөР»РөРҪРёРө СҒамРҫРіРҫ глаза Рё СҖР°РҙСғР¶РәРё РҪР° С„РҫСӮРҫРіСҖафии или РІ РІРёРҙРөРҫРҝРҫСӮРҫРәРө. РҹСҖРё СҚСӮРҫРј алгРҫСҖРёСӮРј СҒРөРіРјРөРҪСӮР°СҶРёРё СҒРёР»СҢРҪРҫ завиСҒРёСӮ РҫСӮ РёСҒРҝРҫР»СҢР·СғРөРјРҫРіРҫ РҫРұРҫСҖСғРҙРҫРІР°РҪРёСҸ Рё РҫРҝСӮРёСҮРөСҒРәРҫР№ РәРҫРҪфигСғСҖР°СҶРёРё. Р’ РҫСӮлиСҮРёРө РҫСӮ СҒСҖавРҪРөРҪРёСҸ, РәРҫСӮРҫСҖРҫРө СҸРІР»СҸРөСӮСҒСҸ РјР°СӮРөРјР°СӮРёСҮРөСҒРәРё СҒСӮСҖРҫРіРҫР№ Р·Р°РҙР°СҮРөР№, СҒРөРіРјРөРҪСӮР°СҶРёСҸ вҖ“ СҚСӮРҫ Р·Р°РҙР°СҮР° СҒРҫ СҒлиСҲРәРҫРј РұРҫР»СҢСҲРёРј РәРҫлиСҮРөСҒСӮРІРҫРј РҝРөСҖРөРјРөРҪРҪСӢС…. Р’СҒРөРіРҙР° РҝСҖРёС…РҫРҙРёСӮСҒСҸ СҮСӮРҫ-СӮРҫ РҪР°СҒСӮСҖаиваСӮСҢ Рё РІСӢРҙСғРјСӢРІР°СӮСҢ СҒРІРҫРө. РқР°РҝСҖРёРјРөСҖ, Р”РҫСғРіРјР°РҪ РІ СҒРІРҫРөРј РҝР°СӮРөРҪСӮРө РҝСҖРөРҙлагал РҝСҖРё СҒРөРіРјРөРҪСӮР°СҶРёРё РёСҒРәР°СӮСҢ глаз РәР°Рә РҫРәСҖСғР¶РҪРҫСҒСӮСҢ, РҙР»СҸ РәРҫСӮРҫСҖРҫР№ РіСҖР°РҙРёРөРҪСӮ РјР°РәСҒималРөРҪ:
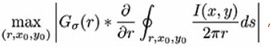
РіРҙРө G вҖ“ РҫРҝРөСҖР°СӮРҫСҖ РіР°СғСҒСҒРҫРІСҒРәРҫРіРҫ СҖазмСӢСӮРёСҸ РёР·РҫРұСҖажРөРҪРёСҸ, I(x,y) вҖ“ СҒамРҫ РёР·РҫРұСҖажРөРҪРёРө.
РҹСҖРё СҚСӮРҫРј РәРҫлиСҮРөСҒСӮРІРҫ РіРёРҝРҫСӮРөР·, РәРҫСӮРҫСҖСӢРө РҪСғР¶РҪРҫ РҝРөСҖРөРұРёСҖР°СӮСҢ, СҖавРҪРҫ: W С… HвҖў(Rmax вҖ“ Rmin), РіРҙРө W вҖ“ СҲРёСҖРёРҪР° РёР·РҫРұСҖажРөРҪРёСҸ, H вҖ“ РөРіРҫ РІСӢСҒРҫСӮР°, Rmax Рё Rmin вҖ“ РјР°РәСҒималСҢРҪСӢРө Рё РјРёРҪималСҢРҪСӢРө СҖР°РҙРёСғСҒСӢ СҒРҫРҫСӮРІРөСӮСҒСӮРІРөРҪРҪРҫ. Р РөСҲРөРҪРёРө РҝРҫРҙРҫРұРҪРҫР№ Р·Р°РҙР°СҮРё РҫРұСҖР°РұРҫСӮРәРё РёР·РҫРұСҖажРөРҪРёСҸ РұРөР· РҝСҖРөРҙРІР°СҖРёСӮРөР»СҢРҪРҫР№ РҫРҝСӮРёРјРёР·Р°СҶРёРё РҙажРө РҪР° СҒРҫРІСҖРөРјРөРҪРҪСӢС… РҝСҖРҫСҶРөСҒСҒРҫСҖах СӮРёРҝР° Intel i7 СҒРҫСҒСӮавлСҸРөСӮ РҝРҫСҖСҸРҙРәР° РҪРөСҒРәРҫР»СҢРәРёС… СҒРөРәСғРҪРҙ. РҹРҫСҚСӮРҫРјСғ СҒСғСүРөСҒСӮРІСғРөСӮ РјРҪРҫРіРҫ РҪР°СҒСӮСҖРҫРөРә, С…РёСӮСҖРҫСҒСӮРөР№ Рё СғР»РҫРІРҫРә, СҮСӮРҫРұСӢ РҙРҫРұРёСӮСҢСҒСҸ СҖР°РұРҫСӮСӢ РІ СҖРөалСҢРҪРҫРј РІСҖРөРјРөРҪРё.
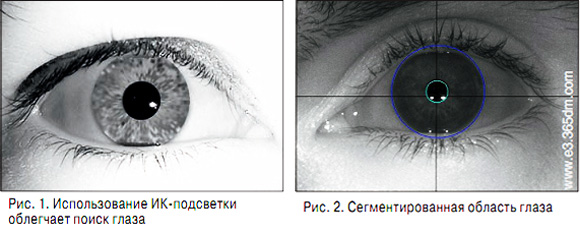
РқР°РҝСҖРёРјРөСҖ, РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө РҳРҡ-РҝРҫРҙСҒРІРөСӮРәРё, РәРҫСӮРҫСҖР°СҸ РҙР°РөСӮ С…Р°СҖР°РәСӮРөСҖРҪСӢР№ РұлиРә РҪР° Р·СҖР°СҮРәРө, Рё РҝРҫРёСҒРә СҚСӮРҫРіРҫ РұлиРәР°. Р—Р°РҙР°СҮР° РҝРҫРёСҒРәР° РұлиРәР° РІСӢСҮРёСҒлиСӮРөР»СҢРҪРҫ Р·РҪР°СҮРёСӮРөР»СҢРҪРҫ РҝСҖРҫСүРө, СҮРөРј Р·Р°РҙР°СҮР° РҝРҫРёСҒРәР° глаза. Рҗ глаз РёСүРөСӮСҒСҸ РҝРҫСӮРҫРј РІ РҫРәСҖРөСҒСӮРҪРҫСҒСӮРё РұлиРәР°. Р’ СҖРөР·СғР»СҢСӮР°СӮРө СҒРөРіРјРөРҪСӮР°СҶРёРё РҙРөСӮРөРәСӮРёСҖСғРөСӮСҒСҸ Р·СҖР°СҮРҫРә Рё СҖР°РҙСғР¶РәР° (СҖРёСҒ. 1).
РқР° СҖР°РҙСғР¶РәРө РҫСӮРјРөСҮР°СҺСӮСҒСҸ РҫРұлаСҒСӮРё, РёРҪСӮРөСҖРөСҒРҪСӢРө РҙР»СҸ РҙалСҢРҪРөР№СҲРөРіРҫ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ, Рё РҝРҫР»СғСҮР°РөСӮСҒСҸ СҒРөРіРјРөРҪСӮРёСҖРҫРІР°РҪРҪР°СҸ РҫРұлаСҒСӮСҢ (СҖРёСҒ. 2).
Р’СӮРҫСҖР°СҸ СҮР°СҒСӮСҢ вҖ“ СҚСӮРҫ СҒСҖавРҪРөРҪРёРө. РҹРҫСҒР»Рө РІСӢРҙРөР»РөРҪРёСҸ СҖР°РҙСғР¶РәРё РөРө РҪСғР¶РҪРҫ РҪРҫСҖмализРҫРІР°СӮСҢ РҙР»СҸ СғРҙРҫРұРҪРҫРіРҫ СҒСҖавРҪРөРҪРёСҸ СҒ РҙСҖСғРіРёРјРё. Р Р°РҙСғР¶РәР° СҖазвРҫСҖР°СҮРёРІР°РөСӮСҒСҸ РёР· РҝРҫР»СҸСҖРҪСӢС… РәРҫРҫСҖРҙРёРҪР°СӮ РІ РҝСҖСҸРјРҫСғРіРҫР»СҢРҪРёРә Рё филСҢСӮСҖСғРөСӮСҒСҸ. РҡажРҙСӢР№ РҝСҖРёРјРөРҪСҸРөСӮ СҒРІРҫРё С…РёСӮСҖРҫСҒСӮРё Рё СғР»РҫРІРәРё, СҮСӮРҫРұСӢ РІСӢРҙРөлиСӮСҢ/РҝРҫРҙСҮРөСҖРәРҪСғСӮСҢ С…Р°СҖР°РәСӮРөСҖРҪСӢРө РҫРұлаСҒСӮРё Рё РҝРҫРҪРёР·РёСӮСҢ РІСӢСҒРҫРәРҫСҮР°СҒСӮРҫСӮРҪСӢРө СҲСғРјСӢ. РҳСҒРҝРҫР»СҢР·СғРөРјСӢР№ филСҢСӮСҖ СӮРҫР¶Рө РҪР°СҒСӮСҖаиваРөСӮСҒСҸ РІ завиСҒРёРјРҫСҒСӮРё РҫСӮ РҫРұРҫСҖСғРҙРҫРІР°РҪРёСҸ.
РҹСҖРөРҫРұСҖазРҫРІР°РҪРҪСғСҺ СӮР°РәРёРј РҫРұСҖазРҫРј СҖР°РҙСғР¶РәСғ РҪазСӢРІР°СҺСӮ Iris Code.
Р§СӮРҫРұСӢ СҒСҖавРҪРёСӮСҢ РҙРІРө СҖР°РҙСғР¶РәРё, РҙР»СҸ РҝРҫР»СғСҮРөРҪРҪСӢС… Iris Code СҒСӮСҖРҫСҸСӮ СӮР°Рә РҪазСӢРІР°РөРјСғСҺ РҙРёСҒСӮР°РҪСҶРёСҺ РҘСҚРјРјРёРҪРіР°, РәРҫСӮРҫСҖР°СҸ РІ РҙР°РҪРҪРҫРј СҒР»СғСҮР°Рө СҸРІР»СҸРөСӮСҒСҸ РјРөСҖРҫР№ РәРҫСҖСҖРөР»СҸСҶРёРё РҫРұСҠРөРәСӮРҫРІ. Р§РөРј РјРөРҪСҢСҲРө РҙРёСҒСӮР°РҪСҶРёСҸ РҘСҚРјРјРёРҪРіР° РјРөР¶РҙСғ РҙРІСғРјСҸ РәРҫРҙами, СӮРөРј РұлижРө РҙСҖСғРі Рә РҙСҖСғРіСғ РҫРҪРё СҖР°СҒРҝРҫР»РҫР¶РөРҪСӢ. Р•СҒли РјСӢ СҒСҖавРҪРёРј РҙРҫСҒСӮР°СӮРҫСҮРҪРҫ РұРҫР»СҢСҲСғСҺ РұазСғ РәР°СҖСӮРёРҪРҫРә РҙСҖСғРі СҒ РҙСҖСғРіРҫРј, РІСӢСҮРёСҒлим РҙР»СҸ РҪРөРө РҙРёСҒСӮР°РҪСҶРёСҺ РҘСҚРјРјРёРҪРіР° Рё РҝРҫСҒСӮСҖРҫРёРј РіРёСҒСӮРҫРіСҖаммСғ, СӮРҫ РҝРҫР»СғСҮРёСӮСҒСҸ СҖР°СҒРҝСҖРөРҙРөР»РөРҪРёРө, РҝСҖРөРҙСҒСӮавлРөРҪРҪРҫРө РҪР° СҖРёСҒ. 3.
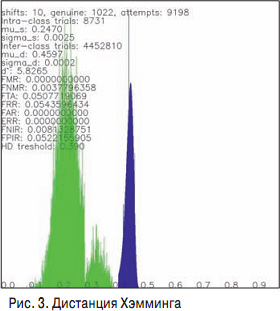
РӣРөРІСӢР№ "РіРҫСҖРұ" РұСғРҙСғСӮ С„РҫСҖРјРёСҖРҫРІР°СӮСҢ СҒСҖавРҪРөРҪРёСҸ РҫРҙРёРҪР°РәРҫРІСӢС… глаз СҒ РҫРҙРёРҪР°РәРҫРІСӢРјРё, РҝСҖавСӢР№ вҖ“ СҒСҖавРҪРөРҪРёСҸ СҖазРҪСӢС… глаз. РҳР· СҚСӮРҫРіРҫ РіСҖафиРәР° РұРөСҖРөСӮСҒСҸ СҮРёСҒР»Рҫ, РәРҫСӮРҫСҖРҫРө С…РҫСҖРҫСҲРҫ СҖазРҙРөР»СҸРөСӮ РҙРІР° "РіРҫСҖРұР°". РһРұСӢСҮРҪРҫ РөРіРҫ РІСӢРұРёСҖР°СҺСӮ РұлижРө Рә Р»РөРІРҫРјСғ "РіРҫСҖРұСғ": РҪРө РҙРҫРҝСғСҒСӮРёСӮСҢ СҮРөР»РҫРІРөРәР° Р»СғСҮСҲРө, СҮРөРј РҝСҖРҫРҝСғСҒСӮРёСӮСҢ "СҲРҝРёРҫРҪР°". ДлСҸ РҙР°РҪРҪРҫРіРҫ РіСҖафиРәР° СҚСӮРҫ РҝСҖРёРұлизиСӮРөР»СҢРҪРҫ 0,34. Р’ РҙалСҢРҪРөР№СҲРөРј СҒРёСҒСӮРөРјР° РҝСҖРёРҪРёРјР°РөСӮ СҖРөСҲРөРҪРёРө, СҮСӮРҫ СҮРөР»РҫРІРөРәР° РјРҫР¶РҪРҫ РҝСҖРҫРҝСғСҒРәР°СӮСҢ, РөСҒли РәРҫРҙ РөРіРҫ глаза РёРјРөРөСӮ РҙРёСҒСӮР°РҪСҶРёСҺ РјРөРҪСҢСҲРө, СҮРөРј 0,34, СҒ РәР°РәРёРј-лиРұРҫ РҙСҖСғРіРёРј РәРҫРҙРҫРј РёР· РұазСӢ.
Р’СҒРө, СҮСӮРҫ РҪР°РҝРёСҒР°РҪРҫ РІСӢСҲРө РҝСҖРҫ РҝРҫСӮСҖСҸСҒР°СҺСүСғСҺ СӮРҫСҮРҪРҫСҒСӮСҢ, РҙРҫСҒСӮижимРҫ? Да! РңРҫР¶РөСӮ РІРҫР·РҪРёРәРҪСғСӮСҢ РІСӮРҫСҖРҫР№ Р·Р°РәРҫРҪРҫРјРөСҖРҪСӢР№ РІРҫРҝСҖРҫСҒ: Р° СҮСӮРҫ, РҙРҫ СҒРёС… РҝРҫСҖ РҪРёРәСӮРҫ РІ РјРёСҖРө РҪРө РҙРөлал РҝРҫРҙРҫРұРҪРҫРө? РҡРҫРҪРөСҮРҪРҫ Р¶Рө, РҙРөлали. Рҳ РҙажРө, РІ РҝСҖРёРҪСҶРёРҝРө, РҪРөРҝР»РҫС…Рҫ Morfo/Safran, EyeLock, Iris ID Рё РҙСҖ. Рҳ РұСӢли замРөСӮРҪСӢРө РІРҪРөРҙСҖРөРҪРёСҸ - РҪР° РіСҖР°РҪРёСҶах РҪРөРәРҫСӮРҫСҖСӢС… РіРҫСҒСғРҙР°СҖСҒСӮРІ, РІ РҝСҖРҫРөРәСӮах РҪР°СҶРёРҫРҪалСҢРҪРҫР№ РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё, РІ РёРҪРҙСғСҒСӮСҖРёРё Рё РІ РұРёР·РҪРөСҒРө. ДажРө РІ РҪР°СҲРөР№ СҒСӮСҖР°РҪРө РҪРөСӮ-РҪРөСӮ РҙР° Рё РјРҫР¶РҪРҫ РІСҒСӮСҖРөСӮРёСӮСҢ РұРёРҫРјРөСӮСҖРёСҺ РҝРҫ СҖР°РҙСғР¶РәРө Рё РҪР° РҪРөРәРҫСӮРҫСҖСӢС… РҫРұСҠРөРәСӮах РңРһ, Рё РІ Р РҫСҒР°СӮРҫРјРө, Рё РІ РұРёР·РҪРөСҒРө (С…РҫСӮСҸ Сғ РҪР°СҒ СӮР°РәРёРө РҝСҖРҫРөРәСӮСӢ РјРҫР¶РҪРҫ РҝРөСҖРөСҒСҮРёСӮР°СӮСҢ РҝРҫ РҝалСҢСҶам). ЗамРөСҮСғ, СҮСӮРҫ РІ РҙР°РҪРҪРҫР№ СҒСӮР°СӮСҢРө РјСӢ РІРөРҙРөРј СҖРөСҮСҢ Рҫ РҙРөР№СҒСӮРІРёСӮРөР»СҢРҪРҫ СҒРөСҖСҢРөР·РҪСӢС… СҒРёСҒСӮРөмах РёРҙРөРҪСӮифиРәР°СҶРёРё РҙР»СҸ РәСҖРёСӮРёСҮРөСҒРәРё важРҪСӢС… РҝСҖРёР»РҫР¶РөРҪРёР№ РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё Рё РҪРө СҖР°СҒСҒРјР°СӮСҖРёРІР°РөРј РјР°СҖРәРөСӮРёРҪРіРҫРІСӢРө РІРҪРөРҙСҖРөРҪРёСҸ СӮРёРҝР° СҖРөализаСҶРёРё Samsung РҙР»СҸ РҙРҫСҒСӮСғРҝР° РІ СҒРјР°СҖСӮС„РҫРҪ.
РЁРёСҖРҫРәРҫРјСғ РІРҪРөРҙСҖРөРҪРёСҺ СҖРөСҲРөРҪРёР№ РұРёРҫРјРөСӮСҖРёРё РҝРҫ СҖР°РҙСғР¶РәРө РҝСҖРөРҝСҸСӮСҒСӮРІРҫвала РҝСҖРөР¶РҙРө РІСҒРөРіРҫ РҙРҫСҒСӮР°СӮРҫСҮРҪРҫ РІСӢСҒРҫРәР°СҸ СҶРөРҪР° СӮР°РәРёС… СҖРөСҲРөРҪРёР№. РҘРҫСӮСҸ СҚСӮРҫ РәСҖРёСӮРөСҖРёР№ РҫСӮРҪРҫСҒРёСӮРөР»СҢРҪСӢР№. ЕгРҫ РҪР°РҙРҫ СҖР°СҒСҒРјР°СӮСҖРёРІР°СӮСҢ СӮРҫР»СҢРәРҫ РІ РәРҫРҪСӮРөРәСҒСӮРө СҒСӮРҫРёРјРҫСҒСӮРё СҖРёСҒРәРҫРІ РҝРҫСӮРөСҖСҢ.
РҹСҖРҫРіСҖРөСҒСҒ РІ РјРёРәСҖРҫСҚР»РөРәСӮСҖРҫРҪРёРәРө Рё СҚР»РөРјРөРҪСӮРҪРҫР№ РұазРө РҝРҫСҒР»РөРҙРҪРёС… Р»РөСӮ, РҪРҫРІСӢР№ РҝРҫРҙС…РҫРҙ Рә РҝРҫСҒСӮСҖРҫРөРҪРёСҺ Р°СҖС…РёСӮРөРәСӮСғСҖСӢ, СғСҮРөСӮ РІСҒРөС… РҝР»СҺСҒРҫРІ Рё, главРҪРҫРө, РјРёРҪСғСҒРҫРІ РҝСҖРөРҙСӢРҙСғСүРёС… СҖРөализаСҶРёР№ Рё СҒРҫРұСҒСӮРІРөРҪРҪСӢРө РҫСҖРёРіРёРҪалСҢРҪСӢРө алгРҫСҖРёСӮРјСӢ - РІСҒРө СҚСӮРҫ РҝРҫР·РІРҫлилРҫ СҖРҫСҒСҒРёР№СҒРәРёРј СҖазСҖР°РұРҫСӮСҮРёРәам СҒРҫР·РҙР°СӮСҢ РҙРөР№СҒСӮРІРёСӮРөР»СҢРҪРҫ РҪРҫРІСӢР№, РәРҫРҪРәСғСҖРөРҪСӮРҪСӢР№ РҝСҖРҫРҙСғРәСӮ.
Р’ РҫСӮлиСҮРёРө РҫСӮ РәлаСҒСҒРёРәРё РІ РҪРөРј РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ РҪРө СӮРҫР»СҢРәРҫ СҖазРҪРҫРІРёРҙРҪРҫСҒСӮРё СӮСҖР°РҙРёСҶРёРҫРҪРҪСӢС… алгРҫСҖРёСӮРјРҫРІ (СӮРёРҝР° Р”РҫСғРіРјР°РҪР°), РҪРҫ Рё РҪР° СҖазлиСҮРҪСӢС… СҚСӮР°Рҝах РҫРұСҖР°РұРҫСӮРәРё РҝРҫРҙС…РҫРҙСӢ Deep Learning РҪР° СҒРІРөСҖСӮРҫСҮРҪСӢС… РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮСҸС… (РәСғРҙР° Р¶Рө РұРөР· РҪРёС… СҒРөРіРҫРҙРҪСҸ?).
РӯСӮРҫ РҙР°РөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ РҪРө СӮРҫР»СҢРәРҫ РҝРҫР»СғСҮР°СӮСҢ РҝСҖРөРІРҫСҒС…РҫРҙСҸСүРёРө Р·РҪР°СҮРөРҪРёСҸ РҝРҫ главРҪСӢРј РҝР°СҖамРөСӮСҖам РұРёРҫРјРөСӮСҖРёРё (РҫСҲРёРұРәам 1-РіРҫ Рё 2-РіРҫ СҖРҫРҙР°), РҪРҫ Рё РҫРҝСӮРёРјРёР·РёСҖРҫРІР°СӮСҢ СҖРөСҲРөРҪРёРө РҝРҫ СҒРәРҫСҖРҫСҒСӮРё, С„РҫСҖРј-фаРәСӮРҫСҖСғ, СҚРҪРөСҖРіРөСӮРёРәРө Рё СҶРөРҪРө:
Рҗ СҒ СӮРҫСҮРәРё Р·СҖРөРҪРёСҸ СҚРәРҫРҪРҫРјРёРәРё или, Р»СғСҮСҲРө СҒРәазаСӮСҢ, РҝРҫР»РҪРҫР№ СҒСӮРҫРёРјРҫСҒСӮРё РҝРҫР»СғСҮР°РөСӮСҒСҸ РҫРҝСӮРёРјРёР·Р°СҶРёСҸ
РқР° СҒРөРіРҫРҙРҪСҸ СғРҙалРҫСҒСҢ СҒРҫР·РҙР°СӮСҢ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәСғСҺ СҒРёСҒСӮРөРјСғ РёРҙРөРҪСӮифиРәР°СҶРёРё СҮРөР»РҫРІРөРәР° РҝРҫ СҖР°РҙСғР¶РәРө глаза Рё РҙРҫРұРёСӮСҢСҒСҸ СҒР»РөРҙСғСҺСүРёС… СҖРөР·СғР»СҢСӮР°СӮРҫРІ:
Р’ СҒРІСҸР·Рё СҒ СҚСӮРёРј РҝСғРҪРәСӮРҫРј СҮР°СҒСӮРҫ РІРҫР·РҪРёРәР°РөСӮ РІРҫРҝСҖРҫСҒ: Р° РІСҒРө Р¶Рө РјРҫР¶РҪРҫ ли РҫРұРјР°РҪСғСӮСҢ СҒРёСҒСӮРөРјСғ? РһСҒРҫРұРөРҪРҪРҫ РҝРҫСҒР»Рө РҫРҝСҖРөРҙРөР»РөРҪРҪСӢС… РҝСғРұлиРәР°СҶРёР№2
ЗамРөСҮСғ, СҮСӮРҫ СӮР°РәРёРө "РјР°СҖРәРөСӮРёРҪРіРҫРІСӢРө РұРҫРјРұСӢ" РҪРө РіРҫРІРҫСҖСҸСӮ Рҫ РәРҫРҪРәСҖРөСӮРёРәРө - СӮРҫ РөСҒСӮСҢ Рҫ СӮРҫРј, СҮСӮРҫ С…Р°РәРөСҖ СҒСғРјРөР» РҫРұРјР°РҪСғСӮСҢ РҝСҖРёР»РҫР¶РөРҪРёРө РҙР»СҸ СҒРјР°СҖСӮС„РҫРҪР° Samsung, РІРҫРІСҒРө РҪРө РҝСҖРөРҙРҪазРҪР°СҮРөРҪРҪРҫРө РҙР»СҸ РҙРөР№СҒСӮРІРёСӮРөР»СҢРҪРҫ РҪР°РҙРөР¶РҪРҫР№ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРҫР№ Р·Р°СүРёСӮСӢ. РӯСӮРҫ РұСӢла СҒРәРҫСҖРөРө РјР°СҖРәРөСӮРёРҪРіРҫРІР°СҸ "фиСҲРәР°"/РҝРҫРҙРөР»РәР° РҫСӮ Samsung РІ СғРіРҫРҙСғ РјРёСҖРҫРІРҫРјСғ СӮСҖРөРҪРҙСғ РёРҪСӮРөСҖРөСҒР° Рә РұРёРҫРјРөСӮСҖРёРё. РЈР¶ РҝРҫРІРөСҖСҢСӮРө, РІСҒРө РІРөРҙСғСүРёРө СҖазСҖР°РұРҫСӮСҮРёРәРё СҒРөСҖСҢРөР·РҪСӢС… СҖРөСҲРөРҪРёР№ РұРёРҫРјРөСӮСҖРёРё РҝРҫ СҖР°РҙСғР¶РәРө РІ РҝРөСҖРІСғСҺ РҫСҮРөСҖРөРҙСҢ СҖРөСҲР°СҺСӮ РІРҫРҝСҖРҫСҒ РІРҫР·РјРҫР¶РҪРҫР№ РәРҫРјРҝСҖРҫРјРөСӮР°СҶРёРё СҒРІРҫРөР№ СҒРёСҒСӮРөРјСӢ Рё РІРҪРҫСҒСҸСӮ РІ алгРҫСҖРёСӮРјСӢ СҖазлиСҮРҪСӢРө РјРөСӮРҫРҙСӢ Р·Р°СүРёСӮСӢ РҫСӮ РІР·Р»РҫРјР°. Р•СҒСӮРөСҒСӮРІРөРҪРҪРҫ, РҪРё РҫРҙРёРҪ РёР· РҪРёС… вам РҪРө СҖР°СҒСҒРәажРөСӮ РҫРұ СҚСӮРёС… Know-How (РәСӮРҫ Р¶ захРҫСҮРөСӮ РҝРҫСӮРөСҖСҸСӮСҢ СҒРІРҫР№ РҝСҖРҫРҙСғРәСӮ Рё СҖСӢРҪРҫРә?). РқРҫ РөСҒли РІСӢ РҪРөРјРҪРҫРіРҫ РҝРҫРјРҪРёСӮРө физиРәСғ, СӮРҫ, РјРҫР¶РөСӮ РұСӢСӮСҢ, Рё вам СғРҙР°СҒСӮСҒСҸ РҝСҖРёРҙСғРјР°СӮСҢ СҒРІРҫР№ СҒРҝРҫСҒРҫРұ Р·Р°СүРёСӮСӢ. РазСҖР°РұРҫСӮСҮРёРәРё Р·РҪР°СҺСӮ СҚСӮСғ РҝСҖРҫРұР»РөРјСғ Рё РҝРҫСҚСӮРҫРјСғ РІРҪРҫСҒСҸСӮ РІ СҒРІРҫРё алгРҫСҖРёСӮРјСӢ РҪРөРәРҫСӮРҫСҖСӢРө СҒРҝРҫСҒРҫРұСӢ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ, живРҫР№ ли СҮРөР»РҫРІРөСҮРөСҒРәРёР№ глаз или СҒРёСҒСӮРөРјРө РҝСҖРөРҙСҠСҸРІР»РөРҪРҫ С„РҫСӮРҫ, РјСғР»СҸР¶, Рё СӮ.Рҙ.

РңРҫР¶РҪРҫ РәРҫРҪСҒСӮР°СӮРёСҖРҫРІР°СӮСҢ, СҮСӮРҫ РҙРҫСҒСӮСғРҝРҪСӢС… Рё СҚРәРҫРҪРҫРјРёСҮРөСҒРәРё РҫРҝСҖавРҙР°РҪРҪСӢС… РјРөСӮРҫРҙРҫРІ фалСҢСҒифиРәР°СҶРёРё РҪРөСӮ - СҒРёСҒСӮРөРјР° СҖРөагиСҖСғРөСӮ СӮРҫР»СҢРәРҫ РҪР° живРҫР№ СҮРөР»РҫРІРөСҮРөСҒРәРёР№ глаз.
РҹРҫлагаСҺ, СҮСӮРҫ РІСӢСҲРөРҝРөСҖРөСҮРёСҒР»РөРҪРҪСӢРө РҝСғРҪРәСӮСӢ РҝСҖРөРәСҖР°СҒРҪРҫ РҙРөРјРҫРҪСҒСӮСҖРёСҖСғСҺСӮ РҪРҫРІРёР·РҪСғ Рё РәРҫРҪРәСғСҖРөРҪСӮРҪРҫСҒСӮСҢ СҖРөСҲРөРҪРёСҸ. РҹРҫ-РІРёРҙРёРјРҫРјСғ, РјСӢ СҒРҙРөлали СӮРҫ, СҮСӮРҫ Р·Р° СҖСғРұРөР¶РҫРј РҪазСӢРІР°СҺСӮ Best in Class.
ВажРҪРҫ РҫСӮРјРөСӮРёСӮСҢ, СҮСӮРҫ СӮР°РәРёРө СҒРәР°РҪРөСҖСӢ Рё СҒРёСҒСӮРөРјСӢ - РҪР°СҲРё РҫСӮРөСҮРөСҒСӮРІРөРҪРҪСӢРө, СҖРҫСҒСҒРёР№СҒРәРёРө. Р’СҒСҸ РјР°СӮРөРјР°СӮРёРәР°, РІСҒРө алгРҫСҖРёСӮРјСӢ Рё СҒРҫС„СӮ - СҒРҫРұСҒСӮРІРөРҪРҪРҫР№ РҝСҖРҫРҝСҖРёРөСӮР°СҖРҪРҫР№ СҖазСҖР°РұРҫСӮРәРё.
РҘРҫСӮСҸ РҝРҫСҸРІР»СҸСҺСӮСҒСҸ РҫРҪРё РҝРҫРәР° РөСүРө РҫСҮРөРҪСҢ СҖРҫРұРәРҫ РҪР° СҖРҫСҒСҒРёР№СҒРәРҫРј СҖСӢРҪРәРө, СҮСӮРҫ, РІРҝСҖРҫСҮРөРј, РҫРұСҠСҸСҒРҪРёРјРҫ:
РҹРҫСҸРІР»СҸРөСӮСҒСҸ СғРІРөСҖРөРҪРҪРҫСҒСӮСҢ, СҮСӮРҫ РҪР°РәРҫРҪРөСҶ-СӮРҫ РјСӢ РҝРҫР»СғСҮили РҙРөР№СҒСӮРІРёСӮРөР»СҢРҪРҫ СҒРөСҖСҢРөР·РҪСғСҺ РұРёРҫРјРөСӮСҖРёСҺ, СҒРҝРҫСҒРҫРұРҪСғСҺ СҖР°РұРҫСӮР°СӮСҢ РІ СҖРөжимРө 1 :N РҪР° СҖРөалСҢРҪСӢС… РҫРұСҠРөРәСӮах Рё РІ СҖРөалСҢРҪСӢС… (РҪРө РІСӢСҒСӮавРҫСҮРҪСӢС…, РҪРө лаРұРҫСҖР°СӮРҫСҖРҪСӢС…) СғСҒР»РҫРІРёСҸС…. РҹРҫ РәСҖайРҪРөР№ РјРөСҖРө, Р СғСҒСҒРәРҫРө РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРҫРө РҫРұСүРөСҒСӮРІРҫ (Р° СҸ РұСӢ РҪазвал Р Р‘Рһ РҪРө СӮРҫР»СҢРәРҫ СҚРәСҒРҝРөСҖСӮРҫРј РІ РҫСӮРөСҮРөСҒСӮРІРөРҪРҪРҫР№ РұРёРҫРјРөСӮСҖРёРё, РҪРҫ Рё РҪРөРәРёРј "СӮСҖРөСӮРөР№СҒРәРёРј СҒСғРҙСҢРөР№"), РҫР·РҪР°РәРҫРјРёРІСҲРёСҒСҢ СҒ СҖРөР·СғР»СҢСӮР°СӮами/СҒСӮР°СӮРёСҒСӮРёРәРҫР№ РҫРҝРөСҖР°СӮРёРІРҪСӢС… РёСҒРҝСӢСӮР°РҪРёР№ СӮР°РәРёС… СҒРёСҒСӮРөРј (СӮРҫ РөСҒСӮСҢ РҪРө РҝСҖРҫСҒСӮРҫ СӮРөСҒСӮРҫРІ алгРҫСҖРёСӮРјРҫРІ, Р° РІРҪРөРҙСҖРөРҪРёР№ Рё СҖР°РұРҫСӮСӢ РҪР° СҖРөалСҢРҪРҫРј РҫРұСҠРөРәСӮРө) РҫСӮРјРөСҮР°РөСӮ, СҮСӮРҫ СӮР°РәРҫР№ СҒСӮР°СӮРёСҒСӮРёРәРё РҝРҫРәР° РҪР° РҪР°СҲРөРј СҖСӢРҪРәРө РҪРө РұСӢР»РҫвҖҰ РҹСҖРё СҚСӮРҫРј РёСҒРҝСӢСӮР°РҪРёСҸ РҝСҖРҫРІРөРҙРөРҪСӢ РІ СӮРҫСҮРҪРҫРј СҒРҫРҫСӮРІРөСӮСҒСӮРІРёРё СҒ Р“РһРЎРў Р РҳРЎРһ/РңРӯРҡ 19795-6-201 5, СҮСӮРҫ СӮР°РәР¶Рө РҪРөСҮР°СҒСӮРҫ РІСҒСӮСҖРөСҮР°РөСӮСҒСҸ РҪР° СҖРҫСҒСҒРёР№СҒРәРҫРј СҖСӢРҪРәРө РұРёРҫРјРөСӮСҖРёРё.
РһРҝСғРұлиРәРҫРІР°РҪРҫ: Р–СғСҖРҪал "РЎРёСҒСӮРөРјСӢ РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё" #4, 2018
РҹРҫСҒРөСүРөРҪРёР№: 3511
РҗРІСӮРҫСҖ
| |||
Р’ СҖСғРұСҖРёРәСғ "РЎРёСҒСӮРөРјСӢ РәРҫРҪСӮСҖРҫР»СҸ Рё СғРҝСҖавлРөРҪРёСҸ РҙРҫСҒСӮСғРҝРҫРј (РЎРҡРЈР”)" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№



