






Р’ СҖСғРұСҖРёРәСғ "Р’РёРҙРөРҫРҪР°РұР»СҺРҙРөРҪРёРө (CCTV)" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№
ЧаСҒСӮСҢ 1
РЎСӮР°СӮСҢСҸ РҝРөСҮР°СӮР°РөСӮСҒСҸ РІ авСӮРҫСҖСҒРәРҫР№ СҖРөРҙР°РәСҶРёРё
Рң.Р’. Р СғСҶРәРҫРІ
Р“РөРҪРөСҖалСҢРҪСӢР№ РҙРёСҖРөРәСӮРҫСҖ РәРҫРјРҝР°РҪРёРё Megapixel Ltd, Рә.СӮ.РҪ

РўРҫРІР°СҖРёСүРё РҙРҫСҖРҫРіРёРө! РазСҖРөСҲРёСӮРө РІСҒРөС… РІР°СҒ Рё СҒамРҫРіРҫ СҒРөРұСҸ, РөСҒСӮРөСҒСӮРІРөРҪРҪРҫ, РҝРҫР·РҙСҖавиСӮСҢ СҒ РҝРөСҖРІСӢРј РјРёРәСҖРҫСҺРұРёР»РөРөРј - РҝСҸСӮРёР»РөСӮРёРөРј РјРҫРөР№ РҙСҖСғР¶РұСӢ СҒ РёР·РҙР°СӮРөР»СҢСҒСӮРІРҫРј Р“СҖРҫСӮРөРә"! РҳРјРөРҪРҪРҫ РІ 2003-Рј РіРҫРҙСғ РҪР°РәР°СӮал РҝРөСҖРІСғСҺ СҒСӮР°СӮСҢСҺ: "Р’РёРҙРөРҫРҙРөСӮРөРәСӮРҫСҖСӢ -РІР·РіР»СҸРҙ РёР·РҪСғСӮСҖРё'". РҹСҸСӮСҢ Р»РөСӮ - СҚСӮРҫ РјРҪРҫРіРҫ РёР»СҢ малРҫ? Рҗ РәР°Рә РҝРҫСҒРјРҫСӮСҖРөСӮСҢ. Р’ СҖазСҖРөР·Рө СҚРІРҫР»СҺСҶРёРё, СҶивилизаСҶРёРё Рё СҚРјР°РҪСҒРёРҝР°СҶРёРё, Р° СӮР°РәР¶Рө РјРёСҖРҫРІРҫР№ СҖРөРІРҫР»СҺСҶРёРё - СӮСҢС„Сғ, РҝРөСҒСҮРёРҪРәР°! РһРҙРҪР°РәРҫ РөСҒли СҒРҫСҒСҖРөРҙРҫСӮРҫСҮРёСӮСҢСҒСҸ РҪР° РҪР°СғСҮРҪРҫ-СӮРөС…РҪРёСҮРөСҒРәРҫРј РҝСҖРҫРіСҖРөСҒСҒРө, РҫСҒРҫРұРөРҪРҪРҫ РҪР° РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪСӢС… СӮРөС…РҪРҫР»РҫРіРёСҸС… -РҝРөСҖРёРҫРҙ РіРёРіР°РҪСӮСҒРәРёР№! РҹРҫРҝСҖРҫРұСғР№СӮРө РІСҒРҝРҫРјРҪРёСӮСҢ, РәР°РәРёРјРё РұСӢли РәРҫРјРҝСҢСҺСӮРөСҖСӢ РҝСҸСӮСҢ Р»РөСӮ РҪазаРҙ. Рҗ флРөСҲРәРё? РўР°Рә-СӮРҫ РІРҫСӮ. Рһ РҪР°СҲРөР№ РјРёРәСҖРҫРҫСӮСҖР°СҒли -"РһС…СҖР°РҪРҪРҫРө РІРёРҙРөРҫРҪР°РұР»СҺРҙРөРҪРёРө" - СғР¶ Рё РҪРө РіРҫРІРҫСҖСҺ. Р’СҒС‘ РҪР°СҖР°СҒСӮРёР»РҫСҒСҢ СҒРҫ СҒСӮСҖР°СҲРҪРҫР№ СҒРёР»РҫР№: СҒРәРҫСҖРҫСҒСӮСҢ РәРҫРҪСӮСҖРҫР»СҸ, СҮРёСҒР»Рҫ РәР°РҪалРҫРІ, РөРјРәРҫСҒСӮСҢ Р°СҖС…РёРІР° Рё СӮ.Рҙ. Рё СӮ.Рҝ
Рҳ РІСҒС‘ РұСӢ С…РҫСҖРҫСҲРҫ, СӮРҫР»СҢРәРҫ РІРҫСӮ СҒ РөРіРҫ Р’РөлиСҮРөСҒСӮРІРҫРј Р’РёРҙРөРҫРҙРөСӮРөРәСӮРҫСҖРҫРј - РҫРұР»РҫРј РҝРҫР»СғСҮРёР»СҒСҸ! РҡР°РәРёРј РҫРҪ РұСӢР» (РІ РҫРұСүРөР№ РјР°СҒСҒРө) - СӮР°РәРёРј РҫСҒСӮалСҒСҸ. Рҗ РҝРҫСҮРөРјСғ? Да РҝРҫСӮРҫРјСғ, СҮСӮРҫ, РІРёРҙРёРјРҫ, РҪСғР¶РөРҪ РҫРҝСҖРөРҙРөлёРҪРҪСӢР№ СғСҖРҫРІРөРҪСҢ Р·РҪР°РҪРёР№, РҪРө РҫРұлаРҙР°СҸ РәРҫСӮРҫСҖСӢРј, РҪРөРІРҫР·РјРҫР¶РҪРҫ РҝРөСҖРөР№СӮРё РҫСӮ РәРҫлиСҮРөСҒСӮРІР° Рә РәР°СҮРөСҒСӮРІСғ. РЎ РҙСҖСғРіРҫР№ СҒСӮРҫСҖРҫРҪСӢ - РІСҒРөРј СғР¶Рө РҙРҫ ламРҝРҫСҮРәРё. ГлавРҪРҫРө РҝСҖРҫРҙаваСӮСҢ, Р° СҮСӮРҫ - РҪРө важРҪРҫ! Рҳ РҝРҫРҪРөСҒлаСҒСҢ -РҪР°СғСҮРҪСӢРө СҖазСҖР°РұРҫСӮРәРё замРөРҪили PR-РјРөСҖРҫРҝСҖРёСҸСӮРёСҸРјРё СҒРҫ РІСҒРөРјРё РІСӢСӮРөРәР°СҺСүРёРјРё РҝРҫСҒР»РөРҙСҒСӮРІРёСҸРјРё. РҡРҫСҖРҫСҮРө, РәР°Рә СҒРәазал РұСӢ РІРөлиРәРёР№ РҗСҖРәР°РҙРёР№ РайРәРёРҪ "Р’РөСҒСҢ РҝР°СҖ СғСҲёл РІ РіСғРҙРҫРә!!!". РўР°РәРҫРіРҫ РҪР°РҙСғРҙРөли -СғСҲРё завСҸли Сғ Р·Р°РәазСҮРёРәРҫРІ РҫСӮ РІРёРҙРөРҫР°РҪалиСӮРёСҮРөСҒРәРҫРіРҫ СғРіР°СҖР°. Р–СғСҖРҪалСӢ РҝСҒРөРІРҙРҫРҪР°СғСҮРҪСӢРө РІСӢРҝСғСҒРәР°СҺСӮСҒСҸ, СҒСӮР°СӮСҢРё РёРҙРёРҫСӮСҒРәРёРө РҝРёСҲСғСӮСҒСҸ.., СҚС…!
Р§СӮРҫ Р¶ РІСӢ, СҖРөРұСҸСӮР°, РҙРөлаРөСӮРө - СӮРөС…РҪРҫ-РҝРҫС…РјРөР»СҢРө РҪРө Р·Р° РіРҫСҖами! РҳР»СҢ РІСӢ СҖР°СҒСҒСҮРёСӮСӢРІР°РөСӮРө РәР°Рә РІ РәРёРҪРҫ "Р–РөРҪРёСӮСҢРұР° БалСҢзамиРҪРҫРІР°": "РЎ РҙРөРҪСҢгами, мамРөРҪСҢРәР°, РјСӢ Рё РұРөР· СғРјР° РҝСҖРҫживРөРј"! РҡСғРҝРёРј РҝСҖРҫС„РөСҒСҒРҫСҖРҫРІ СҒ РҙРҫСҶРөРҪСӮами РҪР° РәРҫСҖРҪСҺ - РҫРҪРё Р¶ СӮР°РәРёРө СғРјРҪСӢРө, РІ РҳРҪСӮРөСҖРҪРөСӮРө СӮСғСҒСғСҺСӮСҒСҸ, РІСҒС‘ Р·РҪР°СҺСӮ, Р»СҺРұСӢРө алгРҫСҖРёСӮРјСӢ Р·Р°РҙРөлаСҺСӮ Р»РөРіРәРҫ, РҪР°РҝСҖРёРјРөСҖ, СҮСӮРөРҪРёРө РјСӢСҒР»РөР№ РҝРҫ РҝРҫС…РҫРҙРәРө! РҹР°СҖРҙРҫРҪ - РёР·РІРёРҪРёСӮРө, РҝСҖРҫСҒСӮРҫ РҪРөСҖРІСӢ РҪРё Рә СҮС‘СҖСӮСғ, РҪР°РұРҫР»РөР»Рҫ! Рҗ РҙавайСӮРө РҝРҫ-РҝСҖРҫСҒСӮРҫРјСғ РәР°Рә-СӮРҫ РҝРҫРІСӢСҲР°СӮСҢ СғСҖРҫРІРөРҪСҢ Р·РҪР°РҪРёР№! РЁРәРҫР», СғРІСӢ, РҪРөСӮ, РҙР° Рё РҝСҖРё СӮР°РәРҫРј РҝРҫРҙС…РҫРҙРө РҪРө РҝСҖРөРҙРІРёРҙСҸСӮСҒСҸ. РқСғ, СӮРҫРіРҙР° РҙРҫР·РІРҫР»СҢСӮРө РІРҪРөСҒСӮРё СҒРәСҖРҫРјРҪСӢР№ РІРәлаРҙ, РёСҒС…РҫРҙСҸ РёР· СҒРІРҫРөРіРҫ жизРҪРөРҪРҪРҫРіРҫ РҫРҝСӢСӮР°. РӯСӮРҫ СҮСӮРҫ-СӮРҫ СӮРёРҝР° Р»РөРәСҶРёР№ РҪР° СӮРөРјСғ РёР·Р»РҫР¶РөРҪРёСҸ лиСҮРҪРҫРіРҫ РІРёРҙРөРҪРёСҸ РҝСҖРҫРұР»РөРјСӢ. РҳСӮР°Рә, РҝРҫРөхали - РҪР° РІСӮРҫСҖРҫР№ РІРёСӮРҫРә РІРёРҙРөРҫР°РҪализа!
ДлСҸ РҪР°СҮала Р·Р°РҙР°РҙРёРјСҒСҸ РҫСҒРҪРҫРІРҪСӢРј РІРҫРҝСҖРҫСҒРҫРј: "Рҗ Р·Р°СҮРөРј РҪам РІСҒРө СҚСӮРё РІРёРҙРөРҫРҙРөСӮРөРәСӮРҫСҖСӢ РҪСғР¶РҪСӢ?". Р‘СғРҙРөРј жаСӮСҢ РҙР° РҝРёСҒР°СӮСҢ! Р’РҫСӮ РҫРҪР° СӮСғРҝР°СҸ РјРөСҮСӮР° РҫРұРҫлваРҪРөРҪРҪРҫРіРҫ РҝРҫР»СҢР·РҫРІР°СӮРөР»СҸ: "РҘРҫСҮСғ РІСҒС‘ РІРёРҙРөСӮСҢ, Р° РёРҪРҫРіРҙР° Рё РҫСӮРјРҫСӮР°СӮСҢ, СҮСӮРҫРұ РіРҫР» Р·Р°РұРёСӮСӢР№ СҒРјР°РәРҫРІР°СӮСҢ!". Рҗ СӮРҫР»РәСғ-СӮРҫ? РҹРҫСҚСӮРҫРјСғ СҒРҪРҫРІР° РҝСҖРёРІРөРҙСғ РәР»СҺСҮРөРІСғСҺ С„СҖазСғ РёР·РІРөСҒСӮРҪРҫРіРҫ Р·Р°РұСғРіРҫСҖРҪРҫРіРҫ РҝСҖРҫфи-Р°РҪалиСӮРёРәР° РҡСҖСҚР№РіР° Р”РҫРҪалСҢРҙР°.
РЎРёСҒСӮРөРјСӢ, СҒСӮРҫСҸСүРёРө РјРҪРҫРіРҫ миллиРҫРҪРҫРІ РҙРҫллаСҖРҫРІ, РҝРҫ-РҝСҖРөР¶РҪРөРјСғ РҫСҒРҪРҫРІСӢРІР°СҺСӮСҒСҸ РҪР° СҒРҝРҫСҒРҫРұРҪРҫСҒСӮРё РҫРҝРөСҖР°СӮРҫСҖРҫРІ РҫРұРҪР°СҖСғживаСӮСҢ РҝСҖРҫРёСҒСҲРөСҒСӮРІРёСҸ Рё СҒРҝРҫСҒРҫРұРҪРҫСҒСӮРё РјРөРҪРөРҙР¶РөСҖРҫРІ РҫСҖРіР°РҪРёР·РҫРІР°СӮСҢ СӮР°РәРҫРө РҫРұРҪР°СҖСғР¶РөРҪРёРө РҙРҫлжРҪСӢРј РҫРұСҖазРҫРј. РЎРёСҒСӮРөРјР° РІРёРҙРөРҫРҪР°РұР»СҺРҙРөРҪРёСҸ РұРөР· СҚффРөРәСӮРёРІРҪРҫРіРҫ РјРөС…Р°РҪРёР·РјР° РҫРұРҪР°СҖСғР¶РөРҪРёСҸ РҝРҫРҙРҫРұРҪР° авСӮРҫРјРҫРұРёР»СҺ, РҙРІРёРіР°СӮРөР»СҢ РәРҫСӮРҫСҖРҫРіРҫ РІРәР»СҺСҮРөРҪ, РҪРҫ СҒам РҫРҪ РҪРёРәСғРҙР° РҪРө РҙРІРёР¶РөСӮСҒСҸ. Р’СҒРө СҖР°РұРҫСӮР°РөСӮ, РҪРҫ РҪРёСҮРөРіРҫ РҪРө РҙРҫСҒСӮРёРіР°РөСӮСҒСҸ!
Р’РҫСӮ РҫРҪР°, РіР»СғРұРҫСҮайСҲР°СҸ РјСӢСҒР»СҢ - "РҫРұРҪР°СҖСғР¶РөРҪРёРө"!! РўР°РәРёРј РҫРұСҖазРҫРј, РІРёРҙРөРҫРҙРөСӮРөРәСӮРёСҖРҫРІР°РҪРёРө - СҚСӮРҫ Рё РҪРө "РёРҪСӮРөллРөРәСӮСғалСҢРҪСӢР№" РәСғСҖаж, Рё РҪРө РҝРёР°СҖРҪР°СҸ РұлажСҢ, Р° РҪР°СҒСғСүРҪР°СҸ РҪРөРҫРұС…РҫРҙРёРјРҫСҒСӮСҢ! РқСғ, СӮРҫРіРҙР° РҙавайСӮРө РҪР°СҮРҪём РҫСӮ РҫРұСҖР°СӮРҪРҫРіРҫ: СҮСӮРҫ РҙР»СҸ СҖРөализаСҶРёРё алгРҫСҖРёСӮРјРҫРІ РІРёРҙРөРҫРҙРөСӮРөРәСӮРёСҖРҫРІР°РҪРёСҸ РҙРөлаСӮСҢ РҪРө РҪР°РҙРҫ, РІРҫСӮ СӮР°Рә РјРҪРө РәажРөСӮСҒСҸ. Рҗ РҝРҫСӮРҫРј СғР¶ РҝлавРҪРҫ РҝРөСҖРөР№Рҙём Рё Рә РҙСҖСғРіРёРј РІР°СҖРёР°СҶРёСҸРј РҪР° СӮРөРјСғ.
РҳСӮР°Рә, РҝРөСҖРІСӢРј РҙРөР»РҫРј - РҝСҖРҫСӮРёРІРҫРҝРҫРәазаРҪРҫ СҖР°РұРҫСӮР°СӮСҢ РҝРҫ РёРҪРҙРёРІРёРҙСғалСҢРҪСӢРј РҝРёРәСҒРөлам, СӮРёРҝР° СӮРҫСҮРөСҮРҪРҫРіРҫ РҙРөСӮРөРәСӮРҫСҖР°. РҳС… амРҝлиСӮСғРҙРҪСӢРө Р·РҪР°СҮРөРҪРёСҸ СҲРёРұРәРҫ СҒРёР»СҢРҪРҫ "РіСғР»СҸСҺСӮ" РҝРҫ РҝСҖРёСҮРёРҪРө флСғРәСӮСғР°СҶРёРё РҫСҒРІРөСүРөРҪРёСҸ, РәРІР°РҪСӮРҫРІСӢС… СҲСғРјРҫРІ Рё РҝСҖРҫСҒСӮРҫ РҝРҫРјРөС…. РқРөРҫРұС…РҫРҙРёРјРҫ РҫСҒСғСүРөСҒСӮРІР»СҸСӮСҢ РҫРұСҖР°РұРҫСӮРәСғ РҫРҝСҖРөРҙРөлёРҪРҪРҫР№ Р»РҫРәалСҢРҪРҫР№ РҫРұлаСҒСӮРё - Р°РҝРөСҖСӮСғСҖСӢ, СҮСӮРҫРұСӢ РҝРҫРҪСҸСӮСҢ, РҝСҖРёРҪР°РҙР»РөжиСӮ ли РәРҫРҪРәСҖРөСӮРҪСӢР№ РҝРёРәСҒРөР», РҪР°РҝСҖРёРјРөСҖ, Рә РәРҫРҪСӮСғСҖСғ. Рҳ СҚСӮРҫ РҪР°РҙРҫ РҙРөлаСӮСҢ РҙР»СҸ РІСҒРөС… СӮРҫСҮРөРә РёР·РҫРұСҖажРөРҪРёСҸ - РІ СҒРәРҫР»СҢР·СҸСүРөРј СҖРөжимРө, Р° РҪРө РёРҪСӮРөРіСҖалСҢРҪРҫ РҙР»СҸ РәРІР°РҙСҖР°СӮРҪРҫ-РіРҪРөР·РҙРҫРІСӢС… РҫРұлаСҒСӮРөР№ С„СҖСҚР№РјР°. РҹРҫРІРөСҖСҢСӮРө - СҚСӮРҫ азСӢ.
Р’СӮРҫСҖРҫРө - РҪРё РІ РәРҫРөРј СҒР»СғСҮР°Рө РҪРө РІСӢСҮРёСҒР»СҸСӮСҢ РјРөР¶РәР°РҙСҖРҫРІСғСҺ СҖазРҪРҫСҒСӮСҢ! РҹРҫСҒР»Рө СҚСӮРҫР№ РҝСҖРҫСҶРөРҙСғСҖСӢ РҝРҫР»РҪРҫСҒСӮСҢСҺ СӮРөСҖСҸРөСӮСҒСҸ РёРҪРҙРёРІРёРҙСғалСҢРҪРҫСҒСӮСҢ РәР°РҙСҖРҫРІ. Рҗ РәСҖРҫРјРө СӮРҫРіРҫ, РҪР°СҮРёРҪР°СҺСӮСҒСҸ РҝСҖРҫРұР»РөРјСӢ СҒ РјРөРҙР»РөРҪРҪСӢРјРё РҙРІРёР¶РөРҪРёСҸРјРё - СҖазРҪРҫСҒСӮСҢ СҒСӮР°РҪРҫРІРёСӮСҒСҸ РәСҖРҫС…РҫСӮРҪРҫР№ РҳРјРөРҪРҪРҫ РҪР° РјРөРҙР»РөРҪРҪСӢС… СӮРөСҒСӮах Рё завалилРҫСҒСҢ РұРҫР»СҢСҲРёРҪСҒСӮРІРҫ СҒРёСҒСӮРөРј - РҝРҫСҒРјРҫСӮСҖРёСӮРө СҒРҫРҫСӮРІРөСӮСҒСӮРІСғСҺСүРёРө РјР°СӮРөСҖиалСӢ СӮРөСҒСӮРҫРІ РҪР° РІСӢСҒСӮавРәРө "РҳРҪСӮРөСҖРҝРҫлиСӮРөС…". РҳР»СҢ РҝСҖРҫСҒСӮРҫ РІРәР»СҺСҮРёСӮРө РәР°РәСғСҺ-РҪРёРұСғРҙСҢ РәамРөСҖСғ СҒРҫ РІСҒСӮСҖРҫРөРҪРҪСӢРј РҙРөСӮРөРәСӮРҫСҖРҫРј. РҹРҫРәР° РҪРө взмахРҪС‘СҲСҢ СҖСғРәРҫР№, РәР°Рә СҒР°РұР»РөР№, - РәСҖР°СҒРҪСӢР№ РәРІР°РҙСҖР°СӮ СӮСҖРөРІРҫРіРё РҪРө РҝРҫСҸРІРёСӮСҒСҸ! РҗСӮР°Рә РјРҫР¶РҪРҫ С…РҫСӮСҢ СҒР»РҫРҪР° РјРөРҙР»РөРҪРҪРҫ РІРҪРөРҙСҖСҸСӮСҢ!
РқРҫ РҝРҫСҮРөРјСғ СӮР°Рә РҝСҖРҫРёСҒС…РҫРҙРёСӮ? Да РҝРҫСӮРҫРјСғ, СҮСӮРҫ РјРөР¶РәР°РҙСҖРҫРІР°СҸ СҖазРҪРҫСҒСӮСҢ (РҝСҖРё РҫРҙРҪРҫР№ Рё СӮРҫР№ Р¶Рө СҒРәРҫСҖРҫСҒСӮРё РҫРұСҠРөРәСӮР°) СҒСӮР°РҪРҫРІРёСӮСҒСҸ РІСҒС‘ РјРөРҪРөРө замРөСӮРҪРҫР№ СҒ СғРІРөлиСҮРөРҪРёРөРј СӮРөРјРҝР° РәРҫРҪСӮСҖРҫР»СҸ. РҹСҖРё 25-СӮРё РәР°РҙСҖ/СҒ РјРҫР¶РҪРҫ РІРҫРҫРұСүРө РҪРёСҮРөРіРҫ РҪРө РҝРҫР№РјР°СӮСҢ, Р° РҪР° 3-С… РәР°РҙСҖ/СҒ РІСҖРҫРҙРө СҮСӮРҫ-СӮРҫ РҝРҫСҸРІРёСӮСҒСҸ. РўРҫРіРҙР° РҪРөРәРҫСӮРҫСҖСӢРө алгРҫСҖРёСӮРјРёСҒСӮСӢ РҝРҫСҒСӮСғРҝР°СҺСӮ СҒР»РөРҙСғСҺСүРёРј РҫРұСҖазРҫРј - РҪРө РҫРұРҪРҫРІР»СҸСҺСӮ СӮРөРәСғСүРөРө СҚСӮалРҫРҪРҪРҫРө Р·РҪР°СҮРөРҪРёРө РҙРҫ СӮРөС… РҝРҫСҖ, РҝРҫРәР° РҪРө СҒСҖР°РұРҫСӮР°РөСӮ РҙРөСӮРөРәСӮРҫСҖ, РҝРҫСҒР»Рө СҮРөРіРҫ РҝРөСҖРөР·Р°РҝРёСҒСӢРІР°СҺСӮ РҫРҝРҫСҖРҪСӢР№ С„СҖСҚР№Рј. РһРҙРҪР°РәРҫ СӮР°Рә РјРҫР¶РҪРҫ РҙРҫР¶РҙР°СӮСҢСҒСҸ Рё РіР»СҺРәР° (РҪРө РҝСғСӮР°СӮСҢ СҒ РёР·РІРөСҒСӮРҪСӢРј РәРҫРјРҝРҫР·РёСӮРҫСҖРҫРј) РҫСӮ РёР·РјРөРҪРөРҪРёСҸ СҒамРҫРіРҫ С„РҫРҪР° (СҒРІРөСӮР»РөРөСӮ, СӮРөРјРҪРөРөСӮ, РҫРұлаРәР°, ла-Р»Сғ-лаЕ). Рҗ РәСҖРҫРјРө СӮРҫРіРҫ, РІРҫР·РҪРёРәР°РөСӮ РҙСҖСғРіР°СҸ РҝСҖРҫРұР»РөРјР°. Р•СҒли РІ РҝРҫР»Рө Р·СҖРөРҪРёСҸ - РҪРөСҒРәРҫР»СҢРәРҫ РҫРұСҠРөРәСӮРҫРІ, СӮРҫ РІСҒРөРіРҙР° РұСғРҙРөСӮ РҙРөСӮРөРәСӮРёСҖРҫРІР°СӮСҢСҒСҸ СӮРҫР»СҢРәРҫ СҒамСӢР№ РұСӢСҒСӮСҖСӢР№ РёР· РҪРёС… (РөСҒСӮРөСҒСӮРІРөРҪРҪРҫРіРҫ РІ СғРіР»РҫРІСӢС… СҒРәРҫСҖРҫСҒСӮСҸС…). РўРҫРіРҙР° РҪР°СҮРёРҪР°СҺСӮ РјСғРҙСҖРёСӮСҢ РөСүС‘ РәСҖСғСҮРө - РҫСҖРіР°РҪРёР·СғСҺСӮ СҒСҖазСғ РҪРөСҒРәРҫР»СҢРәРҫ РәР°РҪалРҫРІ РІСӢСҮРёСҒР»РөРҪРёСҸ РјРөР¶РәР°РҙСҖРҫРІРҫР№ СҖазРҪРҫСҒСӮРё СҒ СҖазРҪСӢРјРё РҙРөР»СҢСӮами РҝРҫ РІСҖРөРјРөРҪРё. РҡРҫСҖРҫСҮРө, РІСҒС‘ СҖазСҖР°СҒСӮР°РөСӮСҒСҸ, РәР°Рә СҒРҪРөР¶РҪСӢР№ РәРҫРј. Рҳ РІРҫР·РҪРёРәР°РөСӮ РҙРёР»РөРјРјР° - СҮСӮРҫ СҒСҮРёСӮР°СӮСҢ С„РҫРҪРҫРј, Р° СҮСӮРҫ РҫРұСҠРөРәСӮРҫРј. РЈРіСғ - СӮРҫР»СҢРәРҫ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ РөСүС‘ Рё РҪРө С…РІР°СӮалРҫ! РқРҫ СҒамРҫРө РёРҪСӮРөСҖРөСҒРҪРҫРө СҒРҫСҒСӮРҫРёСӮ РІ СӮРҫРј, СҮСӮРҫ РҪРөРәРҫСӮРҫСҖСӢРө РҫРұСҠРөРәСӮСӢ, РҫСҒСӮР°РҪРҫРІРёРІСҲРёСҒСҢ, РҝРҫ Р»РҫРіРёРәРө РІРөСүРөР№ РҙРҫлжРҪСӢ СҒами РҝСҖРөРІСҖР°СӮРёСӮСҢСҒСҸ РІ С„РҫРҪ. Р’СҒС‘ СҚСӮРҫ РјСӢ РҝРөСҖРөРҝСҖРҫРұРҫвали - СӮРҫР»РәСғ РҪРёРәР°РәРҫРіРҫ!!! Р’РҫСӮ СӮРҫРіРҙР° Рё РҝСҖРёСҲР»РҫСҒСҢ СҒР»РөРіРәР° РҝРҫРёР·СғСҮР°СӮСҢ РҪРөР№СҖРҫфизиРҫР»РҫРіРёСҺ, РҝРҫСҒРәРҫР»СҢРәСғ СҒамСӢРө СҒРҫРІРөСҖСҲРөРҪРҪСӢРө РІРёРҙРөРҫРҙРөСӮРөРәСӮРҫСҖСӢ РҝСҖРёРҙСғмала - РңР°СӮСғСҲРәР° РҹСҖРёСҖРҫРҙР°!! РҳСӮР°Рә, РҪР°СҮРҪём РҝРҫСӮРёС…РҫРҪСҢРәСғ - СҒ глаза. РЎСҖазСғ РҝСҖРёРІРҫР¶Сғ С„СҖазСғ РёР· СҒРҫРұСҒСӮРІРөРҪРҪРҫРіРҫ РҝСҖРҫРёР·РІРөРҙРөРҪРёСҸ: "Р’РёРҙРөРҫРҙРөСӮРөРәСӮРҫСҖСӢ - РІР·РіР»СҸРҙ РёР·РҪСғСӮСҖРё. Р“СҖР°РҪРё РёРҪСӮРөллРөРәСӮР°":
Р”СғРјР°СҺ, РҙР»СҸ РұРҫР»СҢСҲРөР№ СҸСҒРҪРҫСҒСӮРё РҪР°РҙРҫ РҪРөРјРҪРҫРіРҫ СҖР°СҒСҒРәазаСӮСҢ РҫРұ СғСҒСӮСҖРҫР№СҒСӮРІРө глаза, Р° РёРјРөРҪРҪРҫ Рҫ РөРіРҫ РІРёРҙРөРҫСҒРөРҪСҒРҫСҖРө - СҒРөСӮСҮР°СӮРәРө. РһРҝСғСҒСӮРёРј физиРҫР»РҫРіРёСҮРөСҒРәРёРө РҝРҫРҙСҖРҫРұРҪРҫСҒСӮРё, главРҪРҫРө - СҚСӮРҫ РіРөРҫРјРөСӮСҖРёСҸ СҖР°СҒРҝСҖРөРҙРөР»РөРҪРёСҸ СҒРІРөСӮРҫСҮСғРІСҒСӮРІРёСӮРөР»СҢРҪСӢС… СҚР»РөРјРөРҪСӮРҫРІ, РәРҫРёРјРё СҸРІР»СҸСҺСӮСҒСҸ РҝалРҫСҮРәРё (РҝСҖРҫ РәРҫР»РұРҫСҮРәРё, РІРҫСҒРҝСҖРёРҪРёРјР°СҺСүРёРө СҶРІРөСӮ, РіРҫРІРҫСҖРёСӮСҢ РҪРө РұСғРҙРөРј, РҝРҫСҒРәРҫР»СҢРәСғ РёС… РІСҒРөРіРҫ 6 миллиРҫРҪРҫРІ, СҮСӮРҫ РІ 20 СҖаз РјРөРҪСҢСҲРө). Р Р°СҒРҝСҖРөРҙРөР»РөРҪСӢ РҫРҪРё РәСҖайРҪРө РҪРөСҖавРҪРҫРјРөСҖРҪРҫ, РҝСҖРёСҮём РҪаиРұРҫР»РөРө РіСғСҒСӮРҫ РҝСҖРөРҙСҒСӮавлРөРҪСӢ, РІ СӮР°Рә РҪазСӢРІР°РөРјРҫР№ "СҶРөРҪСӮСҖалСҢРҪРҫР№ СҸРјРәРө". Р§СӮРҫРұСӢ РұСӢР»Рҫ РҝРҫРҪСҸСӮРҪРҫ - РҝРөСҖРөРІРҫРҙ СҚСӮРҫР№ Р·РҫРҪСӢ РІСӢСҒРҫРәРҫРіРҫ СҖазСҖРөСҲРөРҪРёСҸ РҪР° СҖР°СҒСҒРјР°СӮСҖРёРІР°РөРјСӢР№ РҫРұСҠРөРәСӮ, СҖавРҪРҫСҒРёР»РөРҪ "РҪР°РөР·РҙСғ" СӮСҖР°РҪСҒС„РҫРәР°СӮРҫСҖР° СҒ 30-35-РәСҖР°СӮРҪСӢРј СғРІРөлиСҮРөРҪРёРөРј.
Р’СҒРө СҚСӮРё РҙР°РҪРҪСӢРө РҝРҫзаимСҒСӮРІРҫРІР°РҪСӢ Сғ РІРөлиРәРҫРіРҫ РҪРөР№СҖРҫфизиРҫР»РҫРіР°, лаСғСҖРөР°СӮР° РқРҫРұРөР»РөРІСҒРәРҫР№ РҹСҖРөРјРёРё Р”СҚРІРёРҙР° РҘСҢСҺРұРөла РёР· РөРіРҫ СҖР°РұРҫСӮСӢ "Глаз, РңРҫР·Рі, Р—СҖРөРҪРёРө4" - фаРҪСӮР°СҒСӮРёСҮРөСҒРәР°СҸ РәРҪРёРіР° СҒ РәР°СҖСӮРёРҪРәами. РҡРҫРјСғ РёРҪСӮРөСҖРөСҒРҪРҫ - РҝРҫСҮРёСӮайСӮРө, РҫСҮРөРҪСҢ СғРІР»РөРәР°СӮРөР»СҢРҪРҫ. РқСғ Р° РөСҒли РІСҖРөРјРөРҪРё РҪРөСӮ, РҝСҖРёРІРөРҙСғ РөСүС‘ РҝР°СҖСғ фаРәСӮРҫРІ. Р’Рҫ-РҝРөСҖРІСӢС…, СҒРөСӮСҮР°СӮРәР° - СҚСӮРҫ СҮР°СҒСӮСҢ РјРҫР·РіР°, РІСӢРҪРөСҒРөРҪРҪР°СҸ РҪР° РҝРөСҖРёС„РөСҖРёСҺ, РҝСҖРёСҮём СғР¶Рө РҪР° РөС‘ СғСҖРҫРІРҪРө РҫСҒСғСүРөСҒСӮРІР»СҸРөСӮСҒСҸ РҪРөСҒлаРұР°СҸ РҫРұСҖР°РұРҫСӮРәР°. Р•СүС‘ Р»РөСӮ 50-60 РҪазаРҙ СҒСҮРёСӮали, СҮСӮРҫ Р·СҖРёСӮРөР»СҢРҪСӢР№ РҪРөСҖРІ РҝСҖРҫСҒСӮРҫ РҝРөСҖРөРҙаёСӮ РёРҪС„РҫСҖРјР°СҶРёСҺ СҒ СҖРөСҶРөРҝСӮРҫСҖРҫРІ (РҝалРҫСҮРөРә Рё РәРҫР»РұРҫСҮРөРә) РҝСҖСҸРјРҫ РІ РјРҫР·Рі! РҰРөРҝР»СҸли РјРёРәСҖРҫСҚР»РөРәСӮСҖРҫРҙСӢ Рё СӮРёС…Рҫ РҫРұалРҙРөвали - РҪРё РҝСҖСҸРјР°СҸ С„РҫРҪРҫРІР°СҸ Р·Р°СҒРІРөСӮРәР°, РҪРё РҙажРө магРҪРёРөРІР°СҸ РІСҒРҝСӢСҲРәР° РҪРө Рҙавали РҪРёРәР°РәРҫРіРҫ СҚффРөРәСӮР°. РӯСӮРҫ вам РҪРө С„РҫСӮРҫРҙРёРҫРҙСӢ СҒ РҝСҖРҫРІРҫРҙами. Рҳ лиСҲСҢ РҝРҫСӮРҫРј СғСҒСӮР°РҪРҫвили, СҮСӮРҫ РҪРөР№СҖРҫРҪРҪР°СҸ Р°РәСӮРёРІРҪРҫСҒСӮСҢ РҪР°СҮРёРҪР°РөСӮСҒСҸ РҝСҖРё РҝСҖРөРҙСҠСҸРІР»РөРҪРёРё СҒРҝРөСҶифиСҮРөСҒРәРёС… СҒРІРөСӮРҫРІСӢС… СҒСӮРёРјСғР»РҫРІ - СҒРІРөСӮР»СӢС… или СӮёмРҪСӢС… РҝСҸСӮРҪСӢСҲРөРә! Р’Рҫ-РІСӮРҫСҖСӢС…, РІСӢСҸСҒРҪРёР»РҫСҒСҢ: Р°РәСҒРҫРҪРҫРІ (РІСӢС…РҫРҙРҫРІ СҒ РіР°РҪглиРҫР·РҪСӢС… РәР»РөСӮРҫРә), СҒРҫСҒСӮавлСҸСҺСүРёС… Р·СҖРёСӮРөР»СҢРҪСӢР№ РҪРөСҖРІ, РІСҒРөРіРҫ-СӮРҫ РҫРәРҫР»Рҫ миллиРҫРҪР°, РҝСҖРёСӮРҫРј, СҮСӮРҫ СҒамих СҖРөСҶРөРҝСӮРҫСҖРҫРІ РҫРәРҫР»Рҫ 125 миллиРҫРҪРҫРІ. РҡСғРҙР° СҮРөРіРҫ РҝРҫРҙРөвалРҫСҒСҢ?
РҳСӮР°Рә, СҮСӮРҫ Р¶Рө "РІРёРҙРёСӮ" РәажРҙР°СҸ РіР°РҪглиРҫР·РҪР°СҸ РәР»РөСӮРәР°, СӮ.Рө. РәР°РәР°СҸ РёРҪС„РҫСҖРјР°СҶРёСҸ РҝРөСҖРөРҙаёСӮСҒСҸ РҝРҫ Р°РәСҒРҫРҪам Р·СҖРёСӮРөР»СҢРҪРҫРіРҫ РҪРөСҖРІР°? РҹРҫСҸРІР»СҸРөСӮСҒСҸ РҝРҫРҪСҸСӮРёРө - "СҖРөСҶРөРҝСӮРёРІРҪРҫРө РҝРҫР»Рө". РЎРҪРҫРІР° РҫСӮСҒСӢлаСҺ Рә РІСӢСҲРөРҪазваРҪРҪРҫР№ РәРҪРёРіРө (СҒСӮСҖ. 50):
РўРөСҖРјРёРҪ "Р РөСҶРөРҝСӮРёРІРҪРҫРө РҝРҫР»Рө" РІ СғР·РәРҫРј СҒРјСӢСҒР»Рө РҫР·РҪР°СҮР°РөСӮ РҝСҖРҫСҒСӮРҫ СҒРҫРІРҫРәСғРҝРҪРҫСҒСӮСҢ СҖРөСҶРөРҝСӮРҫСҖРҫРІ, РҝРҫСҒСӢлаСҺСүРёС… РҙР°РҪРҪРҫРјСғ РҪРөР№СҖРҫРҪСғ СҒРёРіРҪалСӢ СҮРөСҖРөР· РҫРҙРёРҪ или РұРҫР»СҢСҲРөРө СҮРёСҒР»Рҫ СҒРёРҪР°РҝСҒРҫРІ. Р’ Р·СҖРёСӮРөР»СҢРҪРҫР№ СҒРёСҒСӮРөРјРө СҚСӮРҫ РІСҒРөРіРҫ лиСҲСҢ РҪРөРәРҫСӮРҫСҖР°СҸ РҫРұлаСҒСӮСҢ СҒРөСӮСҮР°СӮРәРё...
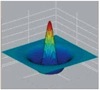
РқСғ Р° РҙалСҢСҲРө - СҒами РҝРҫСҮРёСӮайСӮРө. РҡРҫСҖРҫСҮРө, РІ СҒРөСӮСҮР°СӮРәРө СҖРөСҶРөРҝСӮРёРІРҪСӢРө РҝРҫР»СҸ РёРјРөСҺСӮ С„РҫСҖРјСғ РәСҖСғРіР° СҒ РҝСҖРҫСӮРёРІРҫРҝРҫР»РҫР¶РөРҪРҪСӢРјРё РҝРҫ Р·РҪР°РәСғ РІРҫР·РҙРөР№СҒСӮРІРёСҸРјРё РІ СҶРөРҪСӮСҖРө Рё РҝРөСҖРёС„РөСҖРёРё. РҹСҖРёСҮём СҚСӮРҫ РҪРө РҫР·РҪР°СҮР°РөСӮ, СҮСӮРҫ РІСҒРө СҒРёРіРҪалСӢ РҫСӮ СҖРөСҶРөРҝСӮРҫСҖРҫРІ РІ СҶРөРҪСӮСҖРө РҝСҖРҫСҒСӮРҫ СҒСғРјРјРёСҖСғСҺСӮСҒСҸ СҒ РҫРҙРҪРёРј Р·РҪР°РәРҫРј, Р° РҫСӮ РҝРөСҖРёС„РөСҖРёР№РҪСӢС… - СҒ РҙСҖСғРіРёРј. РқРөСӮ, РҫРҪРё РөСүС‘ Рё РҝРөСҖРөРјРҪРҫжаСҺСӮСҒСҸ РҪР° РәРҫСҚффиСҶРёРөРҪСӮСӢ СҒРҫ Р·РҪР°РәРҫРј (РҝРҫР»РҫжиСӮРөР»СҢРҪСӢРј или РҫСӮСҖРёСҶР°СӮРөР»СҢРҪСӢРј). Р•СҒли РҝРҫСҒСӮСҖРҫРёСӮСҢ РёС… 30-РіСҖафиРә, СӮРҫ РҝРҫР»СғСҮРёСӮСҒСҸ СҮСӮРҫ-СӮРҫ СӮРёРҝР° "РјРөРәСҒРёРәР°РҪСҒРәРҫР№ СҲР»СҸРҝСӢ". РЎСғРјРјР° РІСҒРөС… РәРҫСҚффиСҶРёРөРҪСӮРҫРІ СҖавРҪР° РҪСғР»СҺ!
Р’РҫСӮ РҝРҫСҮРөРјСғ С„РҫРҪРҫРІР°СҸ Р·Р°СҒРІРөСӮРәР° Рё магРҪРёРөРІР°СҸ РІСҒРҝСӢСҲРәР° РҪРө Рҙавали РҪРёРәР°РәРёС… СҖРөР·СғР»СҢСӮР°СӮРҫРІ. ДалРөРө, СҚСӮРё СҖРөСҶРөРҝСӮРёРІРҪСӢРө РҝРҫР»СҸ РҪРө РҪР°РҝРёС…Р°РҪСӢ РұРҫРә Рҫ РұРҫРә РҙСҖСғРі РҙСҖСғРіСғ РІСҒСӮСӢРә, Р° СҖР°СҒРҝРҫР»РҫР¶РөРҪСӢ СҒ СҒРёР»СҢРҪСӢРј РҝРөСҖРөРәСҖСӢСӮРёРөРј РҝРҫ РІСҒРөРјСғ РҝРҫР»СҺ СҒРөСӮСҮР°СӮРәРё. Р‘РҫР»РөРө СӮРҫРіРҫ, РҫРҪРё РөСүС‘ РҫСӮлиСҮР°СҺСӮСҒСҸ Рё РҝРҫ СҖазмРөСҖам Р’ РҫРҙРҪРҫР№ РёР· РјРҫРҙРөР»РөР№ Р·СҖРөРҪРёСҸ СҮРөР»РҫРІРөРәР° (РҝРҫСҒСӮСҖРҫРөРҪРҪРҫР№ РҪР° РұазРө РҪРөР№СҖРҫфизиРҫР»РҫРіРёСҮРөСҒРәРёС… РёСҒСҒР»РөРҙРҫРІР°РҪРёР№) РҝСҖРөРҙРҝРҫлагаРөСӮСҒСҸ РҪалиСҮРёРө 4-С… СӮРёРҝРҫСҖазмРөСҖРҫРІ СҖРөСҶРөРҝСӮРёРІРҪСӢС… РҝРҫР»РөР№. РһРҪРё СғРІРөлиСҮРёРІР°СҺСӮСҒСҸ лиРҪРөР№РҪРҫ, РҝСҖРёРјРөСҖРҪРҫ СҒ РәРҫСҚффиСҶРёРөРҪСӮРҫРј 2. РўР°РәРёРј РҫРұСҖазРҫРј, РҪР°СҲРө Р·СҖРөРҪРёРө РјРҪРҫРіРҫРәР°РҪалСҢРҪРҫ -РјСӢ РәР°Рә РұСӢ "РІРёРҙРёРј" РҫРҙРҪРҫРІСҖРөРјРөРҪРҪРҫ РҪРөСҒРәРҫР»СҢРәРҫ РәР°СҖСӮРёРҪРҫРә СҒ СҖазРҪСӢРј РҝСҖРҫСҒСӮСҖР°РҪСҒСӮРІРөРҪРҪСӢРј СҖазСҖРөСҲРөРҪРёРөРј. РўР°РәРёРө РІРҫСӮ СҮСғРҙРөСҒР°! РЎРөР№СҮР°СҒ РҝРҫРәажСғ. Р‘СғРҙСғ, РәР°Рә РІСҖР°СҮ-РІРёСҖСғСҒРҫР»РҫРі, РёР·РјСӢРІР°СӮСҢСҒСҸ РҪР°Рҙ СҒамим СҒРҫРұРҫР№ - РұРөСҖСғ СҒРҫРұСҒСӮРІРөРҪРҪРҫРө С„РҫСӮРҫ РёР· СҒРІРҫРөР№ Р¶Рө СҒСӮР°СӮСҢРё РҝСҖРҫ РҝСҖР°РәСӮРёСҮРөСҒРәСғСҺ РҝР»РҫСҒРәРҫСҒСӮСҢ РІ РІРёРҙРөРҫРҙРөСӮРөРәСӮРёСҖРҫРІР°РҪРёРё. Р’РҫСӮ - РҝалСҢСҶРөРј СҲРөРІРөР»СҺ (РәСҖР°СҒРҪРөРҪСҢРәРёРј - РҙРөСӮРөРәСӮРҫСҖ СҒСҖР°РұРҫСӮал):

Рҗ СӮРөРҝРөСҖСҢ РҝСҖРҫРҝСғСҒРәР°СҺ СҒРёРө СҮРөСҖРөР· СӮСҖРё "РјРөРәСҒРёРәР°РҪСҒРәРёРө СҲР»СҸРҝСӢ" СҒ РҝСҖРёРұлизиСӮРөР»СҢРҪСӢРј РҪР°СҖСғР¶РҪСӢРј РҙиамРөСӮСҖРҫРј (СҖазмРөСҖ СҖРөСҶРөРҝСӮРёРІРҪРҫРіРҫ РҝРҫР»СҸ) - 10, 20 Рё 40 РҝРёРәСҒРөР» СҒРҫРҫСӮРІРөСӮСҒСӮРІРөРҪРҪРҫ:

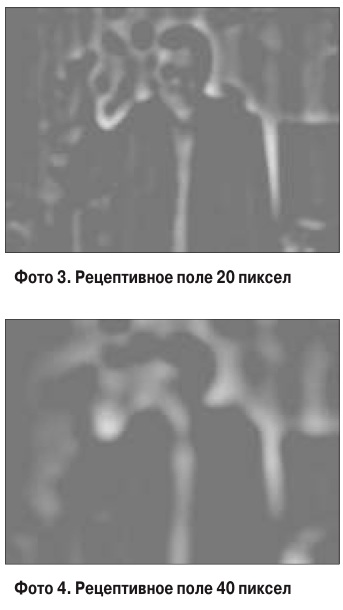
РўР°Рә РІРҫСӮ, СҒРёСҸ РҝСҖРҫСҶРөРҙСғСҖР° РҪазСӢРІР°РөСӮСҒСҸ РҝРҫР»РҫСҒРҫРІРҫР№ филСҢСӮСҖР°СҶРёРөР№. Р§СӮРҫ-СӮРҫ СӮРёРҝР° СҚРәвалайзРөСҖР°, РҪРҫ РҪРө Р·РІСғРәРҫРІРҫРіРҫ, Р° РҙР»СҸ РёР·РҫРұСҖажРөРҪРёР№, РәРҫСӮРҫСҖСӢРө СӮР°Рә Р¶Рө РјРҫР¶РҪРҫ СҖазлРҫжиСӮСҢ РҪР° СҮР°СҒСӮРҫСӮСӢ, РҪРҫ СғР¶Рө РҝСҖРҫСҒСӮСҖР°РҪСҒСӮРІРөРҪРҪСӢРө. Р§РөРј РҫРҪРё РІСӢСҲРө - СӮРөРј Р·Р° РұРҫР»РөРө РјРөР»РәРёРө РҫРұСҠРөРәСӮСӢ РІ РҫСӮРІРөСӮРө, Рё РҪРө СӮРҫР»СҢРәРҫ. Р’СӢСҒРҫРәРёРө СҮР°СҒСӮРҫСӮСӢ РҝСҖРёСҒСғСӮСҒСӮРІСғСҺСӮ РөСүС‘ Рё РҪР° РіСҖР°РҪРёСҶах РәСҖСғРҝРҪСӢС… РҫРұСҖазРҫРІР°РҪРёР№, РіРҙРө СҒРәР°СҮРәРҫРҫРұСҖазРҪРҫ РјРөРҪСҸРөСӮСҒСҸ СҸСҖРәРҫСҒСӮСҢ. РўРөРҝРөСҖСҢ Рҫ "РјРөРәСҒРёРәР°РҪСҒРәРҫР№ СҲР»СҸРҝРө". РҹРҫ-РҪР°СғСҮРҪРҫРјСғ РҫРҪР° РҪазСӢРІР°РөСӮСҒСҸ "РӣР°РҝлаСҒРёР°РҪ РҫСӮ ГаСғСҒСҒРёР°РҪР°". РӯСӮРҫСӮ РҫРҝРөСҖР°СӮРҫСҖ РҫРұлаРҙР°РөСӮ СҒСҖазСғ РҙРІСғРјСҸ СҒРІРҫР№СҒСӮвами - РёРҪСӮРөРіСҖРёСҖСғСҺСүРёРј Рё РҙиффРөСҖРөРҪСҶРёСҖСғСҺСүРёРј. РҹРөСҖРІРҫРө РҝРҫРјРҫРіР°РөСӮ РҙавиСӮСҢ СҲСғРјСӢ Рё РҝРҫРјРөС…Рё СӮРёРҝР° "СҒРҪРөРіР°", РІСӮРҫСҖРҫРө - РҝРҫРҙСҮС‘СҖРәРёРІР°РөСӮ РәРҫРҪСӮСғСҖСӢ. Рҗ РҫРҪРё РҪам РәР°Рә СҖаз Рё РҪСғР¶РҪСӢ! Р•СҒли РәРҫРҪСӮСғСҖСӢ СҒСӮРҫСҸСӮ РҪР° РјРөСҒСӮРө, Р·РҪР°СҮРёСӮ РҙРІРёР¶РөРҪРёСҸ РҪРөСӮ.
РһРұСҖР°СӮРёСӮРө РІРҪРёРјР°РҪРёРө - РҝРҫР»РҫСҒРҫРІР°СҸ филСҢСӮСҖР°СҶРёСҸ РөСүС‘ СғРҪРёСҮСӮРҫжаРөСӮ РҝРҫСҒСӮРҫСҸРҪРҪСғСҺ СҒРҫСҒСӮавлСҸСҺСүСғСҺ! РқСғ СҚСӮРҫ РәРҫРіРҙР° РјРөРҪСҸРөСӮСҒСҸ РҫСҒРІРөСүС‘РҪРҪРҫСҒСӮСҢ - СҒРҫР»РҪСҶРө Р·Р° РҫРұлаРәРҫ СғРөхалРҫ, С„РҫРҪР°СҖРё РјРҫСҖРіР°СҺСӮ Рё СӮ.Рҙ. Рҗ РәР°Рә Р¶Рө РІСҒС‘ СҚСӮРҫ СҖР°РұРҫСӮР°РөСӮ? РқР°Рҙ РёР·РҫРұСҖажРөРҪРёРөРј РІСӢРҝРҫР»РҪСҸРөСӮСҒСҸ РҝСҖРҫСҶРөРҙСғСҖР° СҒРІС‘СҖСӮРәРё - convolution (РҪРө РҝСғСӮР°СӮСҢ СҒРҫ СҒРІРҫСҖР°СҮРёРІР°РҪРёРөРј РҝлаСү-РҝалаСӮРәРё) РқР°РҝСҖРёРјРөСҖ, РІ РҪР°СҲРөР№ СҒРёСҒСӮРөРјРө РұРөСҖС‘СӮСҒСҸ СҸРҙСҖРҫ СҖазмРөСҖРҫРј 13x13 РҝРёРәСҒРөР» (Рё СҚСӮРҫ лиСҲСҢ РҙР»СҸ РІСӢСҒРҫРәРҫСҮР°СҒСӮРҫСӮРҪРҫРіРҫ РәР°РҪала), РІ РәРҫСӮРҫСҖРҫРј Р·Р°РҙР°РҪСӢ РәРҫСҚффиСҶРёРөРҪСӮСӢ "СҲР»СҸРҝСӢ". ДалРөРө РҫРҪРҫ РөР·РҙРёСӮ РҝРҫ РІСҒРөРј РұРөР· РёСҒРәР»СҺСҮРөРҪРёСҸ РјРөСҒСӮам РІС…РҫРҙРҪРҫРіРҫ РёР·РҫРұСҖажРөРҪРёСҸ. Р’СҒСӮали РҪР° СӮРҫСҮРәСғ, РҙР° РІСӢСҮРёСҒлили СҒСғРјРјСғ РҝСҖРҫРёР·РІРөРҙРөРҪРёР№ РәРҫСҚффиСҶРёРөРҪСӮРҫРІ РҪР° Р·РҪР°СҮРөРҪРёСҸ РҫРәСҖРөСҒСӮРҪСӢС… РҝРёРәСҒРөР»РҫРІ, Р·Р°РҝРёСҒали РІ РІСӢС…РҫРҙРҪРҫР№ С„СҖСҚР№Рј (РІ РҫРҙРҪРҫРёРјС‘РҪРҪСғСҺ СӮРҫСҮРәСғ), СҒРјРөСҒСӮилиСҒСҢ, СҒРҪРҫРІР° РІСӢСҮРёСҒлили Рё СӮР°Рә РҙРҫ СғРҝРҫСҖР°. Р•СҒСӮРөСҒСӮРІРөРҪРҪРҫ, РІРҫР·РҪРёРәР°РөСӮ РІРҫРҝСҖРҫСҒ - Р° Сғ РҝСҖРҫСҶРөСҒСҒРҫСҖР° РјРҫСҖРҙР° РҪРө СӮСҖРөСҒРҪРөСӮ СҒ РҝРөСҖРөРҪР°РҝСҖСҸРіСғ? Р’РҫСӮ РІ СҒР»РөРҙСғСҺСүРёР№ СҖаз Рё РҝСҖРҫР°РҪализиСҖСғРөРј.
РһРҝСғРұлиРәРҫРІР°РҪРҫ: Р–СғСҖРҪал "РЎРёСҒСӮРөРјСӢ РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё" #4, 2008
РҹРҫСҒРөСүРөРҪРёР№: 9911
РҗРІСӮРҫСҖ
| |||
Р’ СҖСғРұСҖРёРәСғ "Р’РёРҙРөРҫРҪР°РұР»СҺРҙРөРҪРёРө (CCTV)" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№


